Automating ADF's CI/CD with Full Deployment (Generation 1)
I'll show step-by-step how to configure the The new CI/CD flow described by Microsoft and explain what in which cases I recommend you to use this simplistic, yet, powerful method; I'll also include some best-practices and recommendations.


Introduction
As explained on the series presentation ...
 Hector Sven
Hector Sven
Our first stop into our evolutionary journey towards Selectively deploy ADFs components is to show what Microsoft's recommend for automated publishing documented as The new CI/CD flow
Using this CI/CD is awesome on it's own right by allowing to kick-start the publishing cycle programmatically, as stated in the documentation:
We now have a build process that uses a DevOps build pipeline [...] The build pipeline is responsible for validating Data Factory resources and generating the ARM template instead of the Data Factory UI (Publish button).
A leap forward indeed and for simple use cases more than enough, I'll explain how to set this up, benefits and it's limitations for you to decide if this generation fits your needs.
Setting the stage
Let's use the following scenario for educational purposes: Company "TechTF" has a SQL database named "locasqlserver" hosted "on-premises", that is, accessible only from its local network. They want our team to build up a pipeline using Azure Data Factory to read the contents of a table called "dbo.historicaldata" and truncate & load into an Azure Database the last 6 months of data, ADF pipeline needs to be executed first day of each month, this feature has been classified as a data product and given the name "Recent History".
The "extraction team" is commissioned to build the ADF pipeline, its members are just you and a colleague with the same permissions and complete authority to configure two Azure Data Factory instances, one for development and another for production. The company adheres to modern software development practices, making it imperative to automate the integration of code changes (Continuous Integration) and the delivery of those changes to production (Continuous Deployment). This requirement should be a driving force behind any considerations in architecture design.
The company already have an Azure account as well as an Azure DevOps account (AzDO) up & running with service connections, billing and permission in place, there's a project created to host this and other data products named "RTD" and a Git-repository called "recent-history"
Recommend my series The Anatomy of a Resilient Azure DevOps YAML Pipeline (Series)
In Part 1. Azure Account vs DevOps Account and Part 2. Repository hosting & branching strategy I explain all you need to know to get your environment started.
Procedure
On the next part of the article, I'll explain just the most relevant parts of the code
Deploying the Infrastructure
We are going to create two ADF instances, one that is Git-author enabled for Development, and another one for Production using only Live mode, both were created with BICEP as shown below
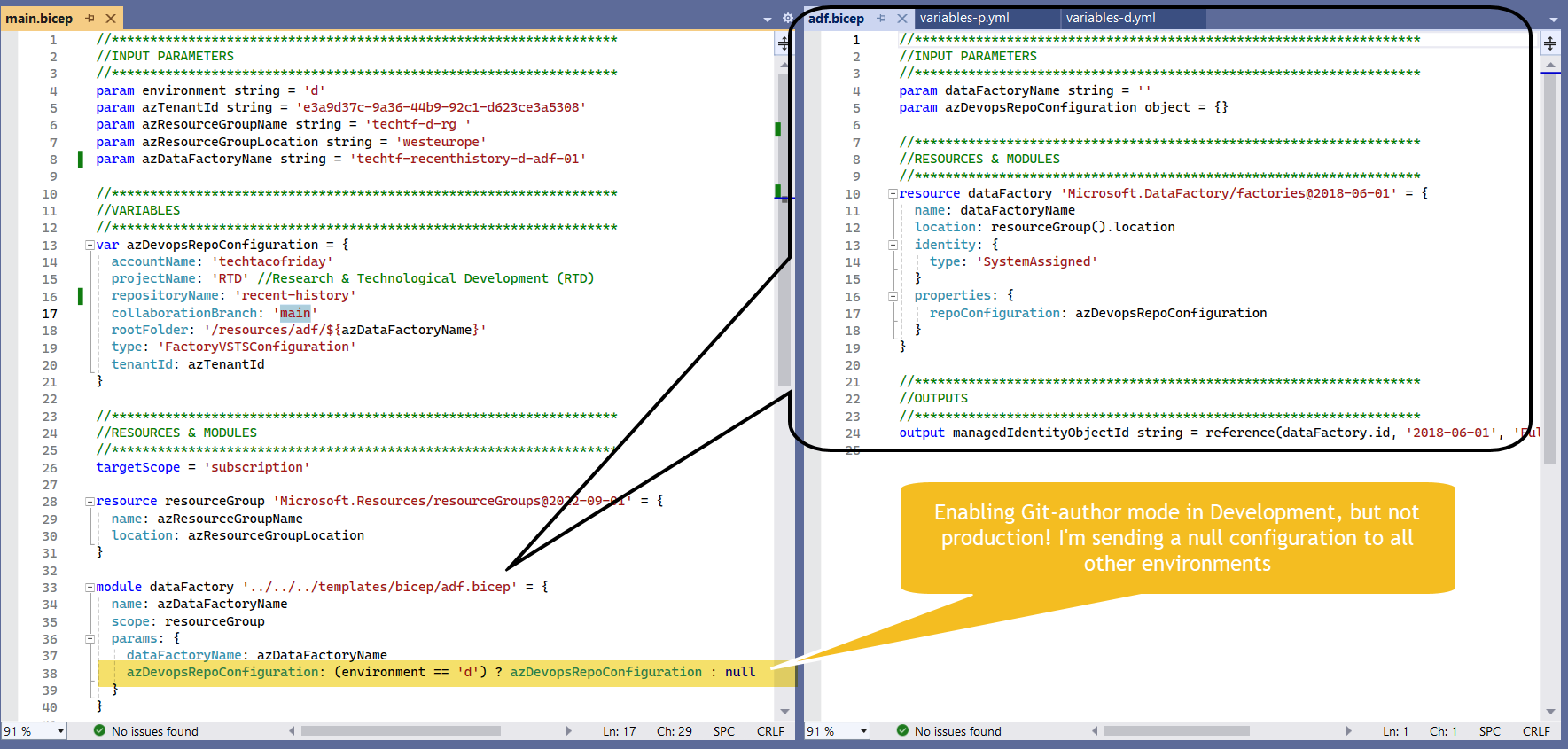
I invite you to read my article Infrastructure-as-code made easy with Bicep language with a detailed explanation on the code.
Hector Sven
Orchestrate the creation of your infrastructure using our Resilient Azure DevOps YAML Pipeline
Hector Sven
Configuring ADF's back-end
- If everything went well with your deployment, navigate to your ADF in Development and create a new feature branch, name this branch something like "feature/yyyymmdd_automate-adf-cicd-full-deployement-g1"
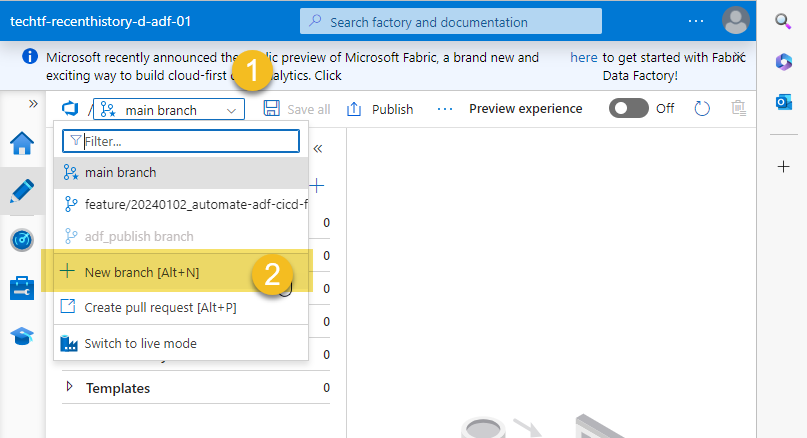
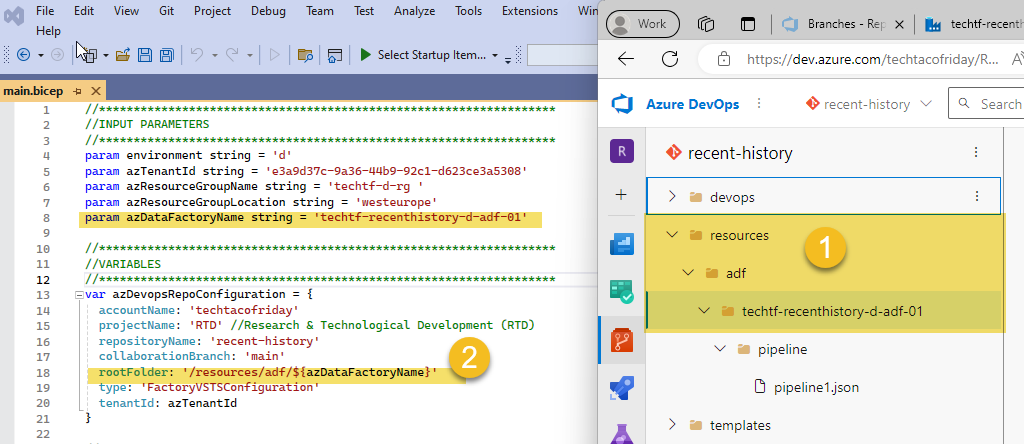
- Crete a temporary pipeline and click Save All, this action will create a new folder in your feature branch (1) from the path defined for rootFolder in BICEP (2)
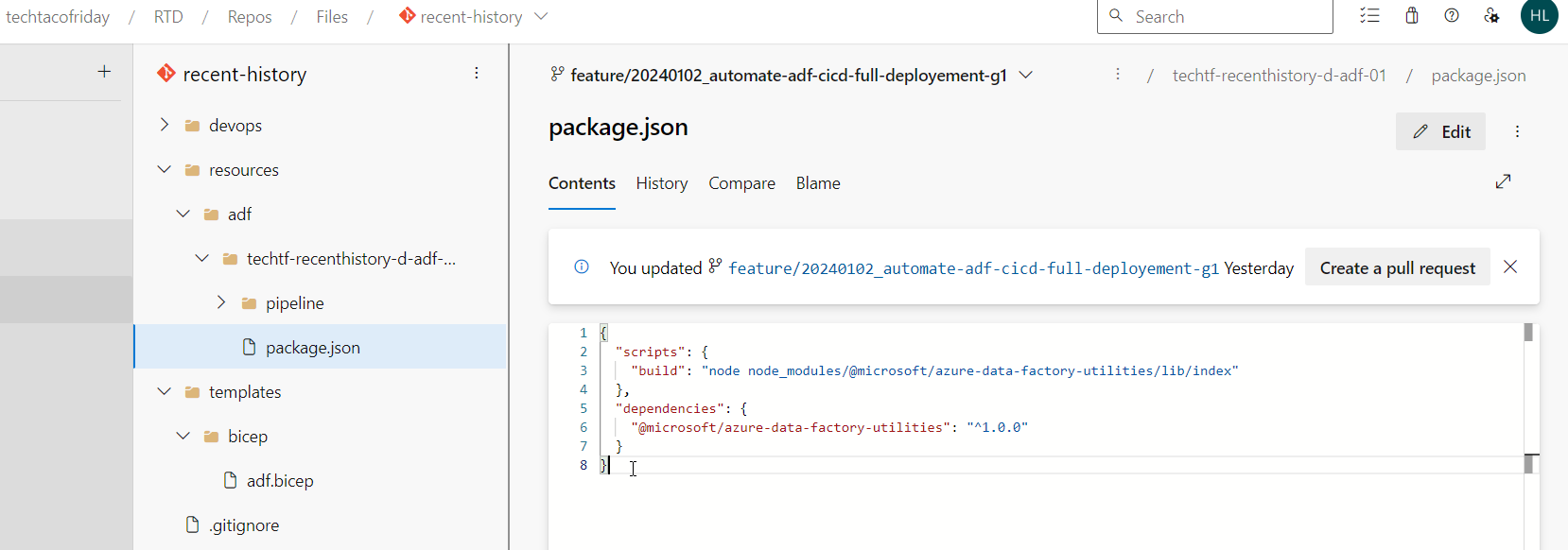
- Add to our feature branch the file package.json, add the following code provided by Microsoft on The new CI/CD flow ... should look like this.
Configuring AzDO YAML pipeline
I'm going to explain additions made to include the code provided by Microsoft on article The new CI/CD flow and to show you how to implement article's note:
[...] when deploying one would still need to reference the documentation on stopping and starting triggers to execute the provided script.
I'm assuming at this point that you will be using the same Resilient Azure DevOps YAML Pipeline to create the infrastructure, therefore, I'm not showing nor explaining those here.
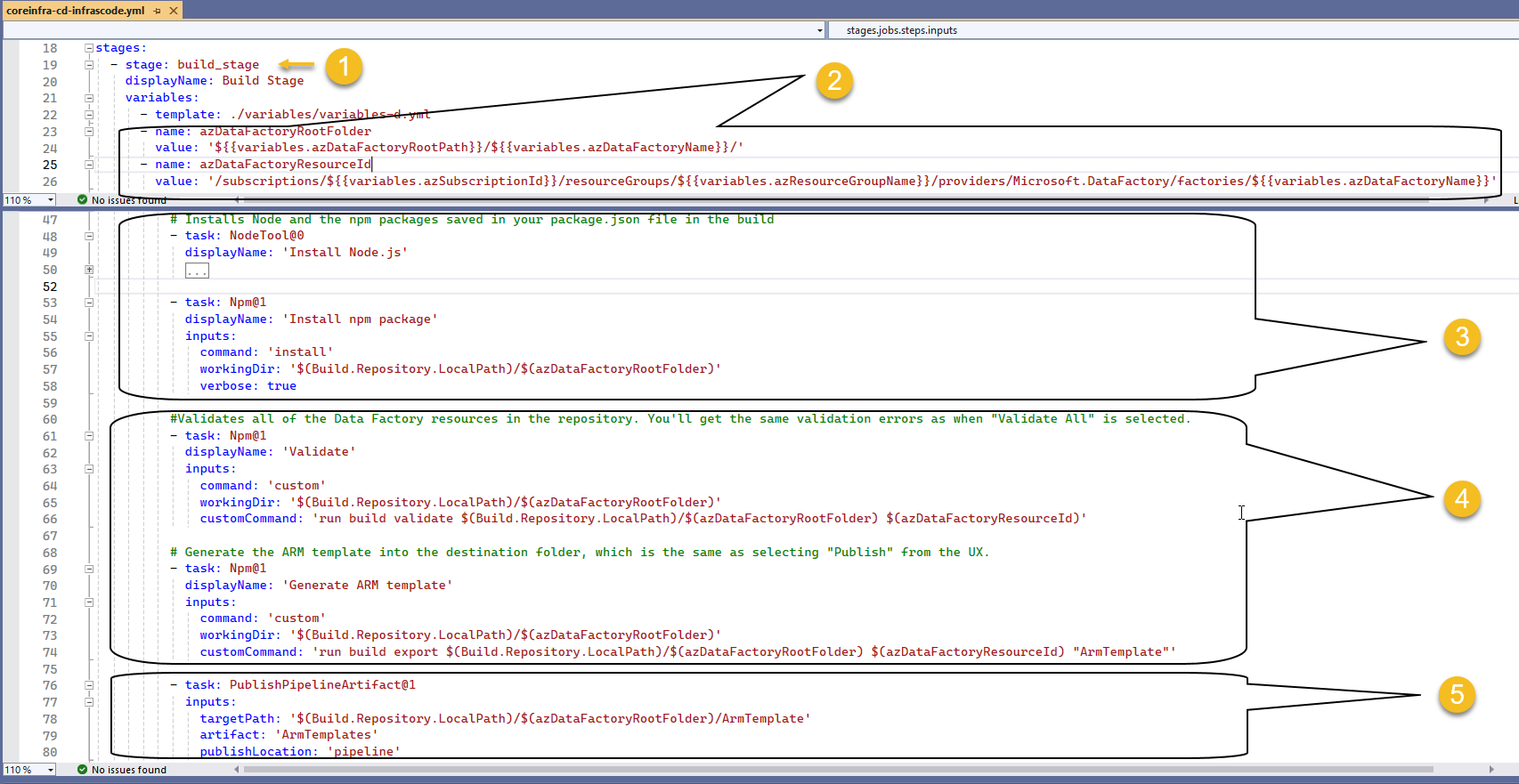
- Within our build_stage (1), let's add a couple of local variables (2) that would help us to enhance our code readability, replace placeholders in the code from MSFT with our variables and adding the steps to install Npm packages (3), validate & generate the ARM template (4) and Publish the ARM template as an artifact.
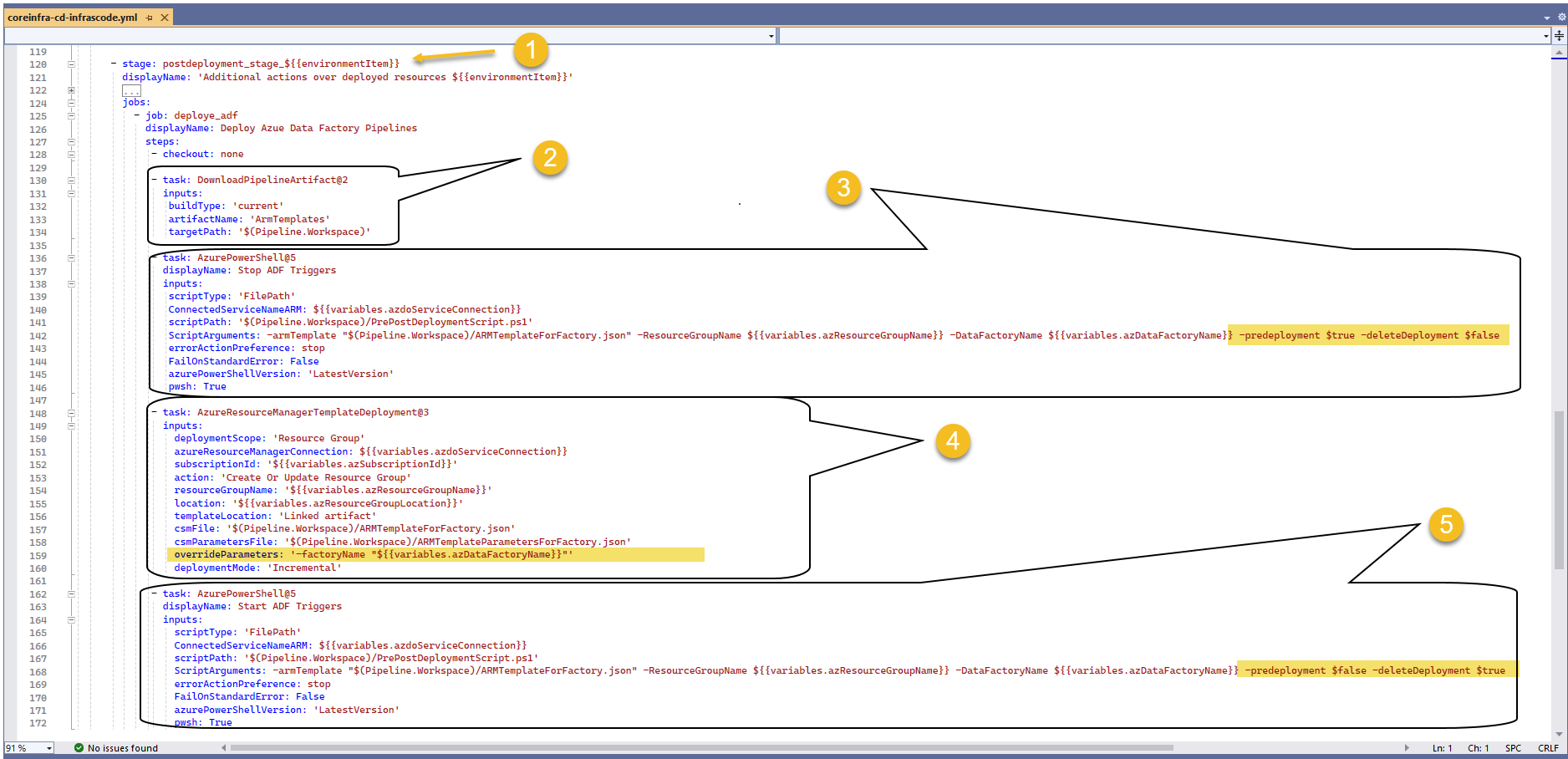
- Within our postdeployment_stage (1), we first download (2) our published artifact from previous build stage, next, we need to STOP any triggers before deploying our components, this is done using an script included automatically while we generate the ARM template (3) we can now publish our content to ADF's live-mode (4), as highlighted the trick is to override the name of the factory name to target other environments 😉 ... finally, we START any previously stop triggers (5)
Use-cases
Now that you've seen how to implement this approach, I would like to highlight the following implications:
- We package in the ARM template everything committed into the branch, that is, all pipelines, datasets, linked services, etc. the whole ADF as exists in the branch
- To modify the ARM template created from the source with the target values, we do so by overriding the values of input parameters, in this simple example it is just one, but I'm sure the number in a real-world scenario will be much bigger.
- It is mandatory to STOP ALL active triggers in the target before deploying a new version and RE-START afterwards
So, this is an excellent solution while any of the above implications are not impediments for you, I mean, if the follow statements are true:
- "It is ok to deploy the whole content of ADF every single time we would like to publish into other environments, we are aware & accept that unfinish/untested pipelines could be included"
- "Basically this ADF will only serve a single data product, hence, we consider all its components as a unity as we deploy it as such to other environments"
- "Our ADF setup is really simple, we just have a few linked services that had to be adjusted to target other environment, hence, override the configuration is completely manageable"
- "It's ok to STOP any active triggers during deployment, we can schedule the deployment of our latest changes on ADF pipelines at times we know triggers are not scheduled to run"
- "We want just a prof-of-concept ADF set-up to showcase or understand how an automated CI/CD cycle works, we don't need a more complex approach at this time"
Perhaps you can relate to some of this statements and conclude that this is just right for you, also, you check on the code, create your pipeline and everything works as expected, if so, congratulations... hope this works great for your Company/Project 😁🥂!!!
Call for action
Get the code automate-adf-cicd-full-deployment-g1 and try it out!!! If this solution is not fit for your purpose, the I suggest you to read my next article where I will explain how to improve our ADF CI/CD cycle using a selective deployment to overcome all of this limitations 😉🤞 below is the subscription button... wish you all the best!



