Automating ADF's CI/CD with Selective Deployment on Shared instances (Generation 3)
This would be our final leap forward where I will divide ADF components into two groups two groups: Core and Data-Product; I'll explain why I think this is a good approach for enterprise scale setups where you might have a team dedicated to provide infrastructure services.


Introduction
It is now the time for the last article planned for the series...
 Hector Sven
Hector Sven
In this article I will expand on the contents presented in the previous Automating ADF's CI/CD with Selective Deployment (Generation 2), but the code will be self-sufficient for you try it out 😉
Setting the stage
The same requirements for data products "Recent History" and "TS Ingestion" defined on the "Setting the stage" section from prev. article Automating ADF's CI/CD with Selective Deployment (Generation 2), the "extraction team" team would be also the same BUT in this case, they DO NOT HAVE THE AUTHORITY to configure Azure Data Factories, this has been delegated to a "platform team".
The primary objective of the "platform team" is to enhance the reusability of Azure Data Factory (ADF) by ensuring that ADF-core components, such as linked services, are designed to be generic through the use of parameters, also controlling configurations that could potentially generate excessive costs like Integration Runtimes.
The "extraction team" will keep complete authority over pipelines, datasets, triggers and dataflows as these are data product-specific; using this approach it is expected our ADF factory to be able to balance between accommodate many different data products with minimal effort and ensuring overall governance and cost control.
In this article I discuss a bit more on this concept if you're interested 😉
Hector Sven
Procedure
On the next part of the article, I'll explain just the most relevant parts of the code
I described in detail in prev. article the procedures to 1) Deploying the Infrastructure, 2) Configuring ADF's back-end, so, not going to include here... I'm going to jump right into 3) Create Workspaces in ADF
As discussed on this section, "extraction team" is correct to include in each data product's Filter file only the pipelines, datasets and triggers that belongs to it.
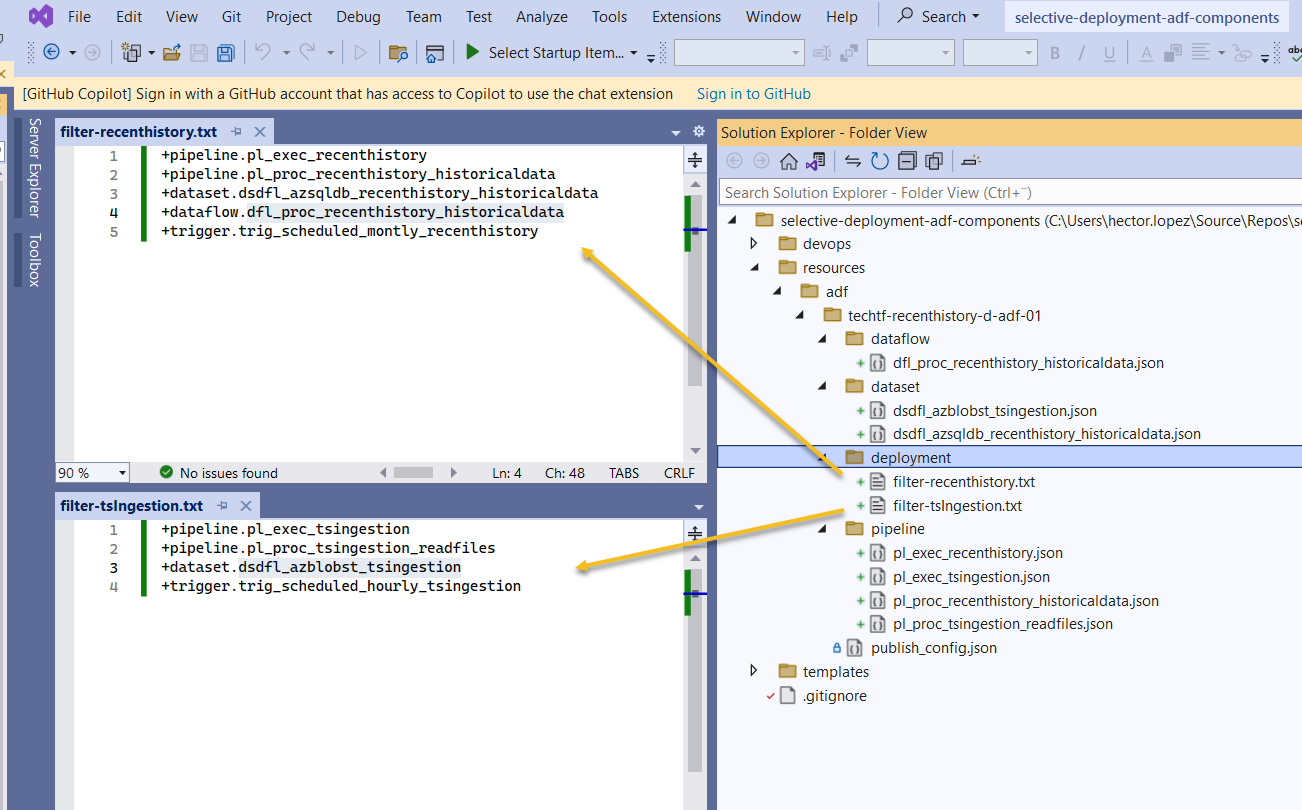
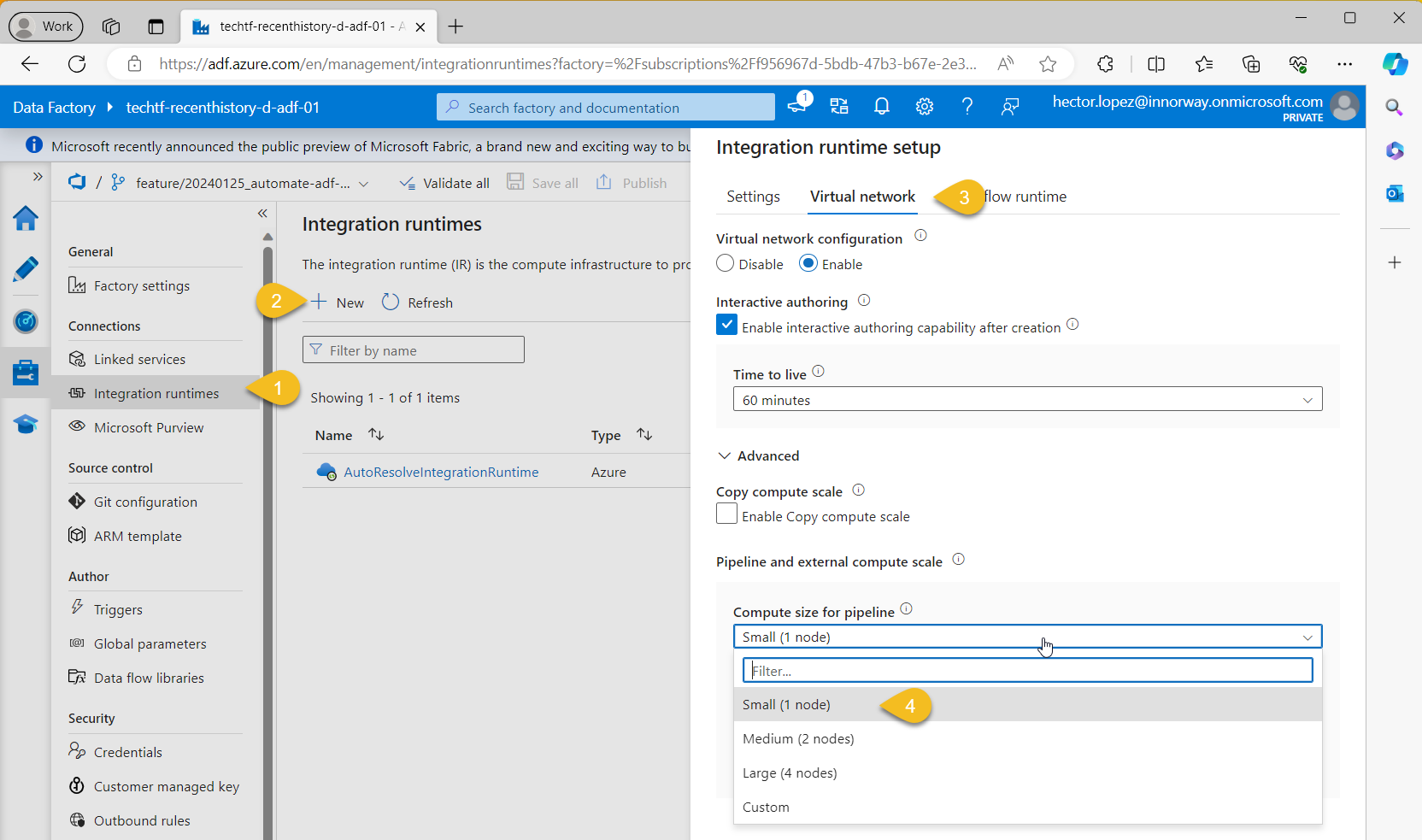
Our "platform team" will also have its workspace within our Shared ADF, let's give it the name adfcoreinfra and treat it the same way as any other data product, INCLUDING (+) only the components they are responsible and EXCLUDING (-) the ones they are not 😉, to clarify, let's assume that the project would like to minimize the costs for our ADF development instance by running with the minimal compute size and allocate more on production, hence, we create a new Integration runtime (IR) as follow
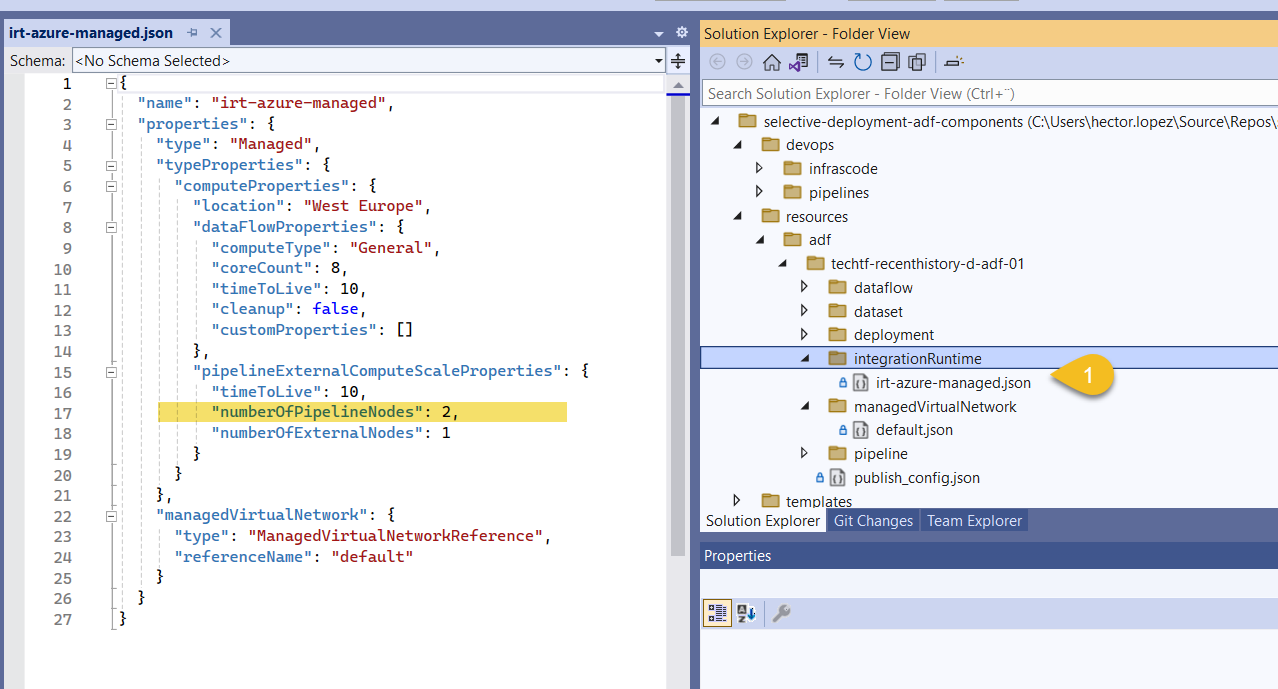
Save your changes and check on your feature branch, as expected, ADF created a new folder integrationRuntime and within, the new's IR's json file.
So finally, platform team's Filter file for adfcoreinfra would be like this.
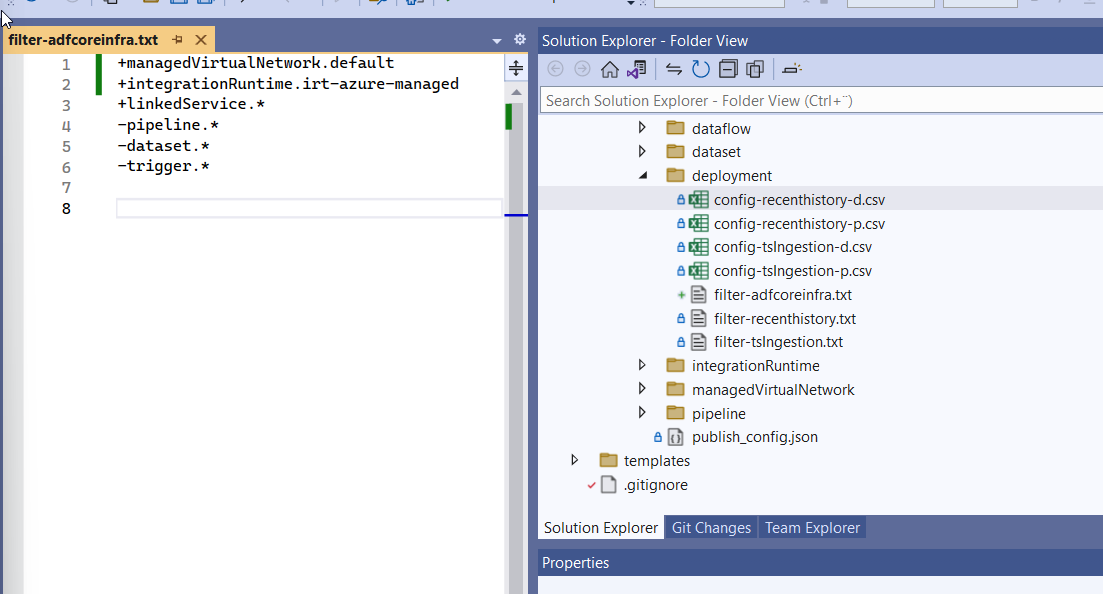
And it's Config file for our development environment like, notice how the path should match the json as shown below
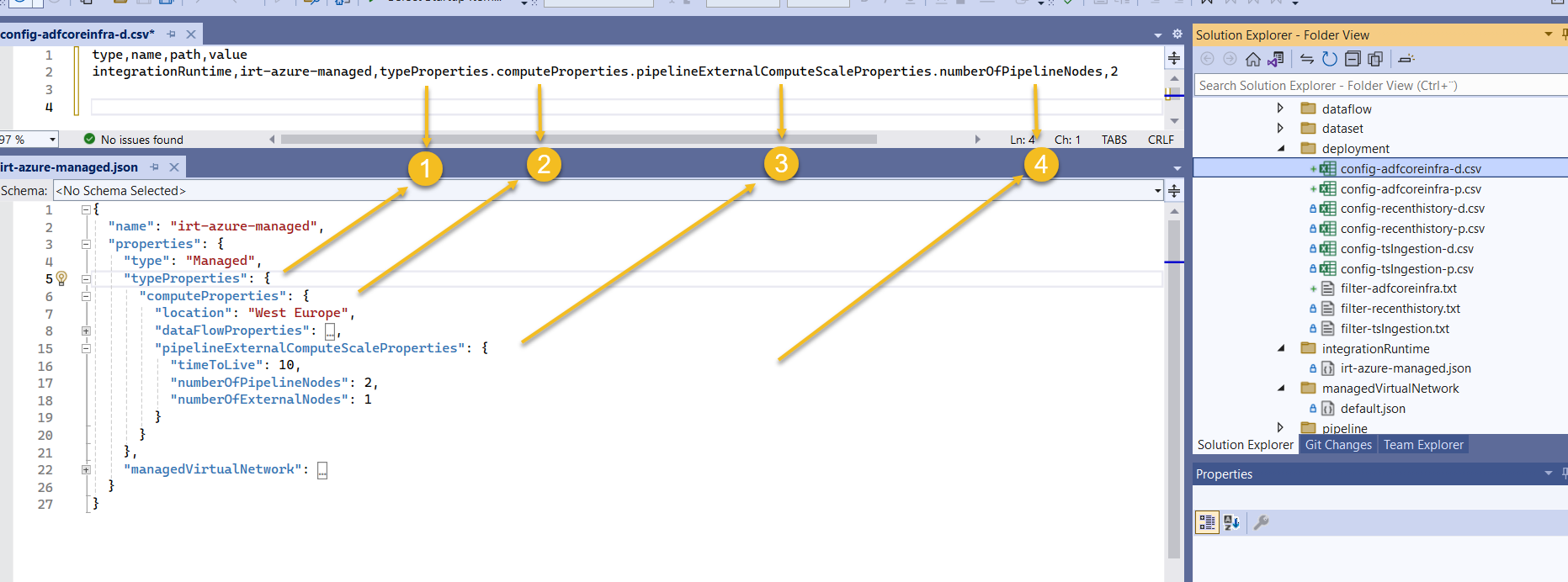
I guess you already know how the Config file for production should look like, but still 😉...

Now you can proceed to 4) Installing the extension and 5) Configuring AzDO YAML pipeline described in detail in prev. article
Call for action
Get the code automate-adf-cicd-selective-deployment-on-shared-instances-g3 and try it out!!! If you like to get my next article directly via email, below is the subscription button... wish you all the best!



