Dataverse Meets Fabric -Comparing Dataverse Sync Options
Compare the two official ways to sync Dataverse data with Microsoft Fabric—Link to Fabric (Direct) and Link via Azure Synapse. Understand the pros, cons, use cases, and cost differences to choose the right path for your BI architecture.

Introduction
In the prev. article I explain why Microsoft Fabric makes strategic sense for Dataverse. Let's us know see what option do we have to make it happen 😉
This article is Part 2 of the Dataverse Meets Fabric (Series) If you landed here first, you might want to check out the full series to get the broader context.
In earlier articles
Setting the Stage
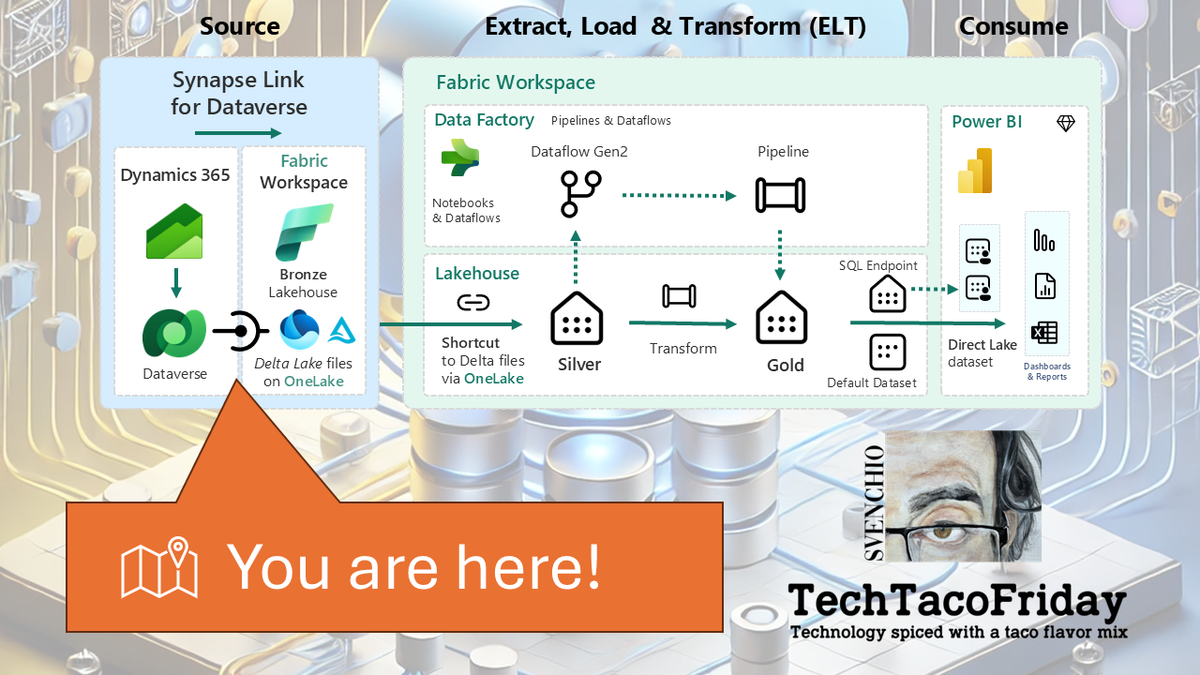
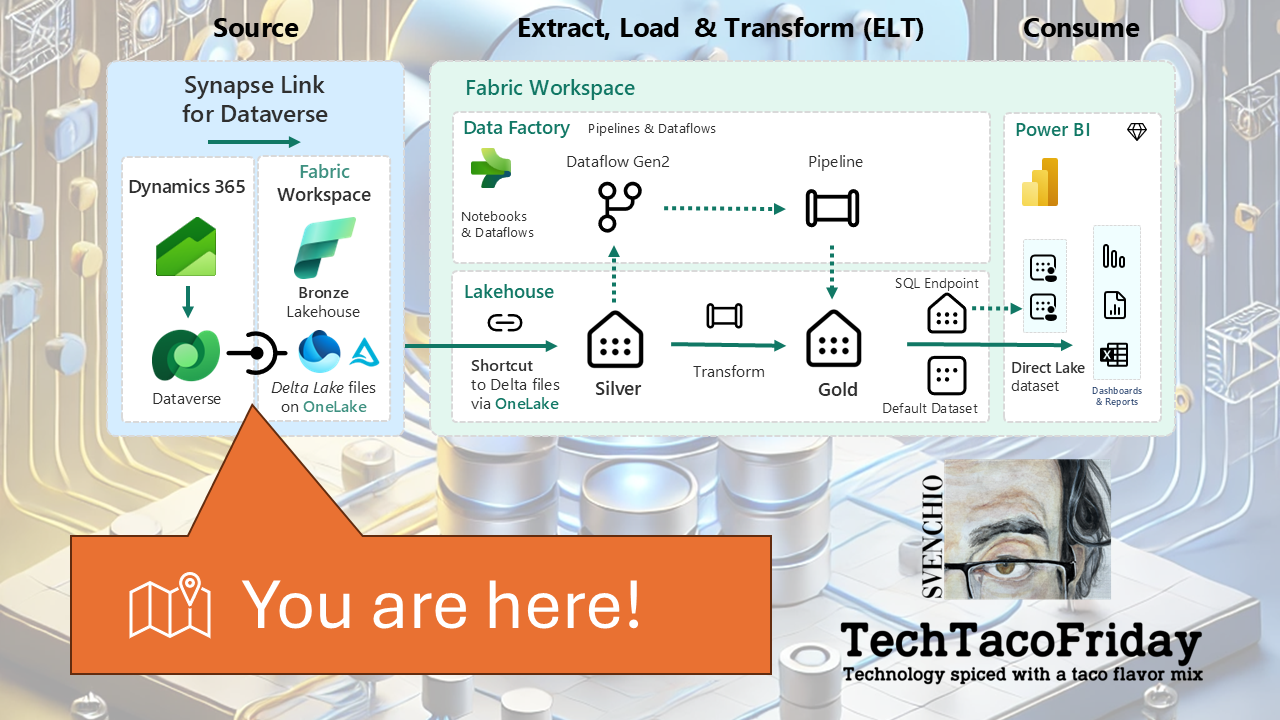
Once you've made the strategic decision to bring your Dynamics 365 (Dataverse) data into Microsoft Fabric, the next question becomes how to do it. Microsoft officially supports two integration paths for syncing Dataverse data into Fabric:
- Link via Azure Synapse Analytics
- Link to Microsoft Fabric (Direct)
Both are capable—but they differ significantly in setup, control, performance, and cost; understanding these differences is critical to choosing the right approach for your organization’s architecture, governance model, and licensing strategy.
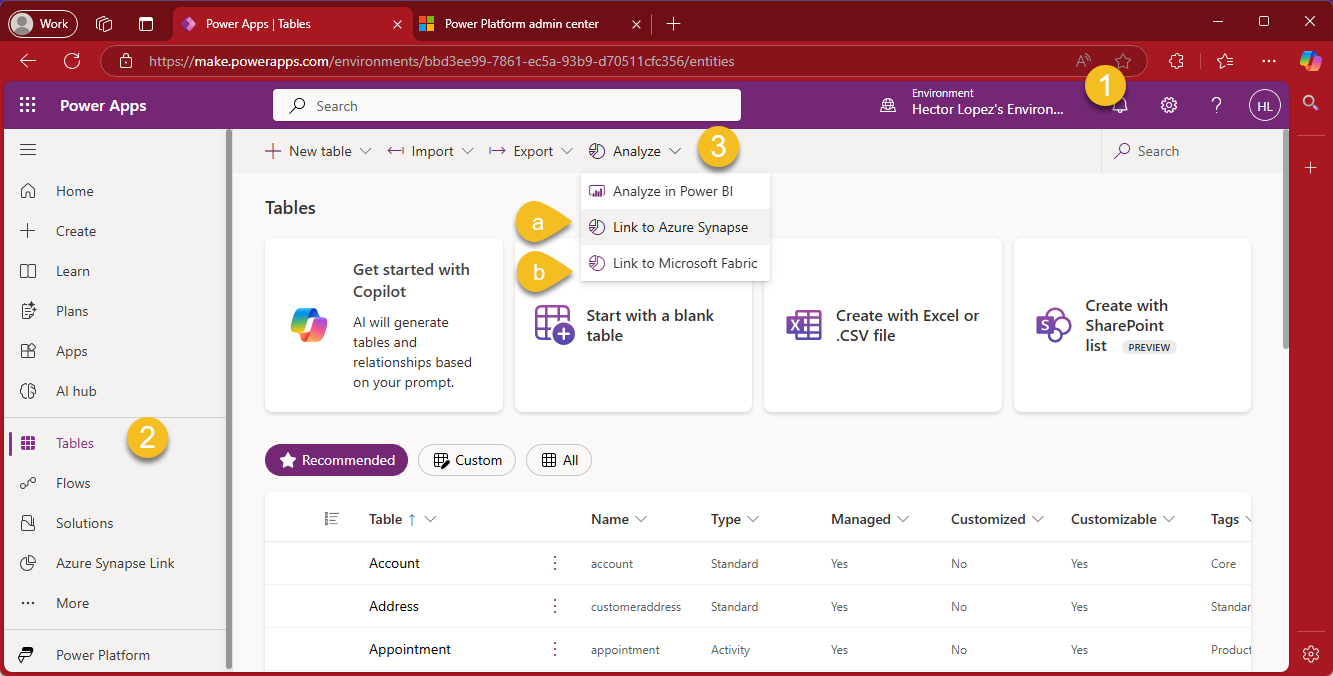
Before we begin, I recommend confirming that you have access to your Power Apps environment. Go to your Power Apps Portal—the central web-based interface for creating and managing apps within the Microsoft Power Platform (1), click on Tables (2) and Analyze (3), as shown in the image below, we have two options (a) Link to Azure Synapse and (b) Link to Microsoft Fabric"
Link to Azure Synapse
This option has been available longer and is built for organizations with existing investments in Azure data services.
If you do not currently use Synapse, this approach requires a more involved setup: you must provision an Azure Synapse workspace, a Spark pool for processing, and a dedicated Azure Data Lake Gen2 storage account.
[...] service supports initial and incremental writes for table data and metadata. Any data or metadata changes in Dataverse are automatically pushed to the Azure Synapse metastore and Azure Data Lake [...] without you needing to set up refresh intervals. (Ref. What is Azure Synapse Link for Dataverse?)
| Pros | Cons |
|---|---|
| Granular control over which tables to sync | More complex setup with Azure components |
| Leverages existing Synapse and ADLS resources | Requires Spark pool, storage configuration, and permissions management |
| Good fit for advanced data engineering and integration scenarios | Data lands in CSV format—requires further transformation for analytics use |
| Can integrate into broader Azure data pipelines | Manual step needed to link into Fabric |
| Flexible for multi-system integration or hybrid cloud strategies | Higher maintenance and potentially higher cost over time |
Link to Microsoft Fabric
This is the newest and most seamless method, designed for simplicity and tight integration within the Fabric ecosystem. You initiate the link directly from the Power Platform environment using the Maker Portal. Once set up, Fabric automatically provisions a Lakehouse within your selected workspace and begins syncing all available Dataverse tables in near real-time. These tables are stored in Delta Lake format, enabling high-performance querying, compatibility with medallion architecture patterns, and native integration with Power BI via Direct Lake.
[...] creates a direct and secure Link between your data in Dataverse and a Fabric workspace. [...] the system creates an optimized replica of your data in delta parquet format [...] using Dataverse storage such that your operational workloads aren't impacted. This replica is governed and secured by Dataverse and stays within the same region as your Dataverse environment while enabling Fabric workloads to operate on this data.
| Pros | Cons |
|---|---|
| Seamless Fabric-native experience | No option to select specific tables (syncs all) |
| Auto-syncs all Dataverse tables in Delta Lake format | Potential for unnecessary data bloat |
| No need to provision Azure resources | Still a relatively new offering—some advanced features may be limited |
| Ideal for Power BI and medallion architecture | Less control for complex data engineering needs |
| Low maintenance and fast to implement | Currently lacks advanced transformation support |
Link to Fabric vs. Azure Synapse Link
In a nutshell ...
| Feature | Link to Fabric (Direct) | Link via Azure Synapse Analytics |
|---|---|---|
| Integration Approach | No-copy, no-ETL direct integration into Microsoft Fabric. Ideal for Power BI and medallion architecture. | Data is exported to your own Azure Data Lake; integration with Synapse, Fabric, and other Azure tools is manual. |
| Data Residency | Data remains in Dataverse and is virtually exposed in Fabric’s Lakehouse using Delta Lake format. | Data is copied to your own Azure Data Lake Gen2 storage account in CSV format. You are responsible for access control. |
| Table Selection | All available Dataverse tables are synced by default (no selective sync currently). | System administrators can select specific tables to sync—offering more control and efficiency. |
| Storage Consumption | Consumes additional Dataverse storage capacity within your tenant’s Fabric environment. | Consumes your own Azure storage, compute, and integration resources (Spark, Synapse pipelines, etc.). |
| Governance & Access | Fully integrated with Microsoft 365 security (AAD), Purview, and Power BI. | Custom setup required for security, permissions, and lineage tracking across Azure services. |
Conclusion
Both integration paths are powerful—but they serve different needs.
| Link to Fabric (Direct) | Link via Azure Synapse Analytics |
|---|---|
| You want fast, low-code setup fully integrated with Microsoft Fabric | You need selective control over which Dataverse tables to sync |
| You're focused on Power BI and medallion architecture | You're already using Azure Synapse, Spark, or other engineering tools |
| You prefer simplicity and minimal infrastructure management | You require complex transformations or multi-source data integration |
| You want all Dataverse tables available by default in Fabric | You want to minimize storage usage by syncing only specific tables |
| You're looking for near real-time analytics with minimal setup | You need granular control over scheduling and data flows |
Whatever your path, understanding the trade-offs upfront will save you time and headaches later.
Call to Action
In the next articles, I’ll show you how to implement each option step-by-step, including Infrastructure-as-Code templates to automate your environment provisioning.
Stay tuned and subscribe to the blog! If you’ve already started exploring one of these paths, I’d love to hear what’s working (or not) for your team... let’s keep the conversation going 😁🤞



