Deploying Notebooks across environments with DevOps YAML Pipelines
Learn how to use DevOps YAML pipelines to create artifacts from collections of Python files and effortlessly deploy them to Databricks workspaces. Gain insights into optimizing your workflow for efficiency and reliability, ensuring smooth transitions between environments


Welcome back 😁! This is Part 3 of the series ...
 Hector Sven
Hector Sven
Setting the stage
I'm assuming that most of the people with interest on this article are already familiar with Azure Databricks and, from the development perspective, the difference between writing notebooks in the Workspace vs Repos, nonetheless, allow me to dive into the differences:
- Databricks Workspaces: A workspace in Databricks is an environment for accessing all of your Databricks assets into folders and provides access to data objects and computational resources
- Databricks Repos: Repos are Databricks folders whose contents are co-versioned together by syncing them to a remote Git repository; using a Databricks repo, you can develop notebooks in Databricks and use a remote Git repository for collaboration and version control
So, do we need both? and if so, why? And the answer is Yes, because of the branching strategy I chose and explain in this article Resilient AzDO YAML Pipeline - Modern software development practices
The codebase in this context will be Databricks notebooks, its content (e.g. Python scripts) are version-controlled through Databricks Repos and eventually deployed from development branches to a Databricks Workspaces in production-like environments 😁
Solution
On the next part of the article, I'll explain just the most relevant parts of the code
Once again, I'm going to use the same stages and structure of the Resilient Azure DevOps YAML Pipeline
Create the artifacts
In this stage of the deployment, we select and copy the files checked-in the yaml's pipeline context branch (1) (read more on steps.checkout: self) to be publish as a named artifact.
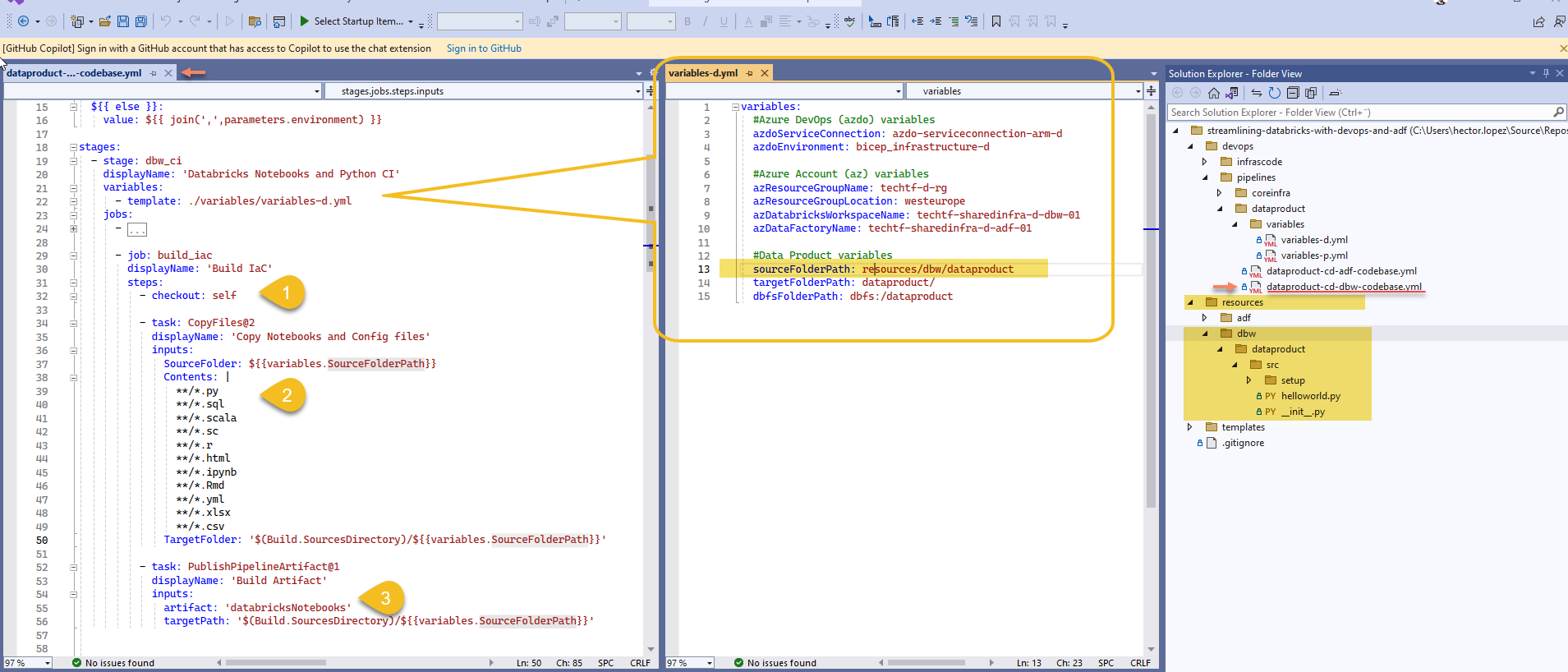
Why the copy files task (2)? The reason is to filter only file types accepted by Databricks, for instance, text files (*.txt) are not allowed in Databricks; we publish article databricksNotebooks (3)
Getting the agent ready
The following tasks prepare the agent to interact with a Databricks workspace
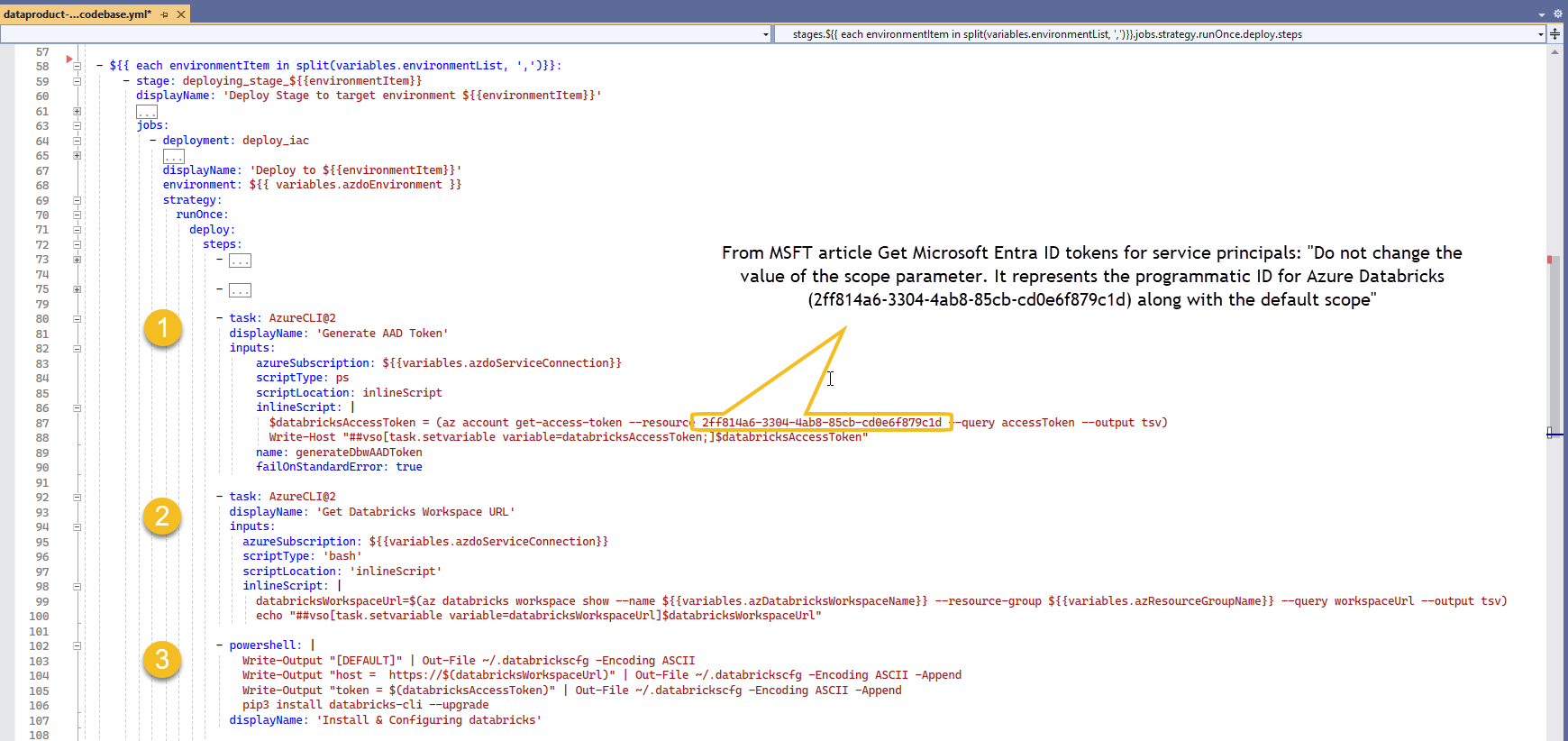
First we create an access token (1), proceed by retrieving workspaces' URL (2), and we use these information to create a [DEFAULT] configuration profile in the .databrickscfg file (3) to quickly run the rest of commands.
Deploy notebooks to workspace
We finally proceed with the actual deployment of the notebooks!
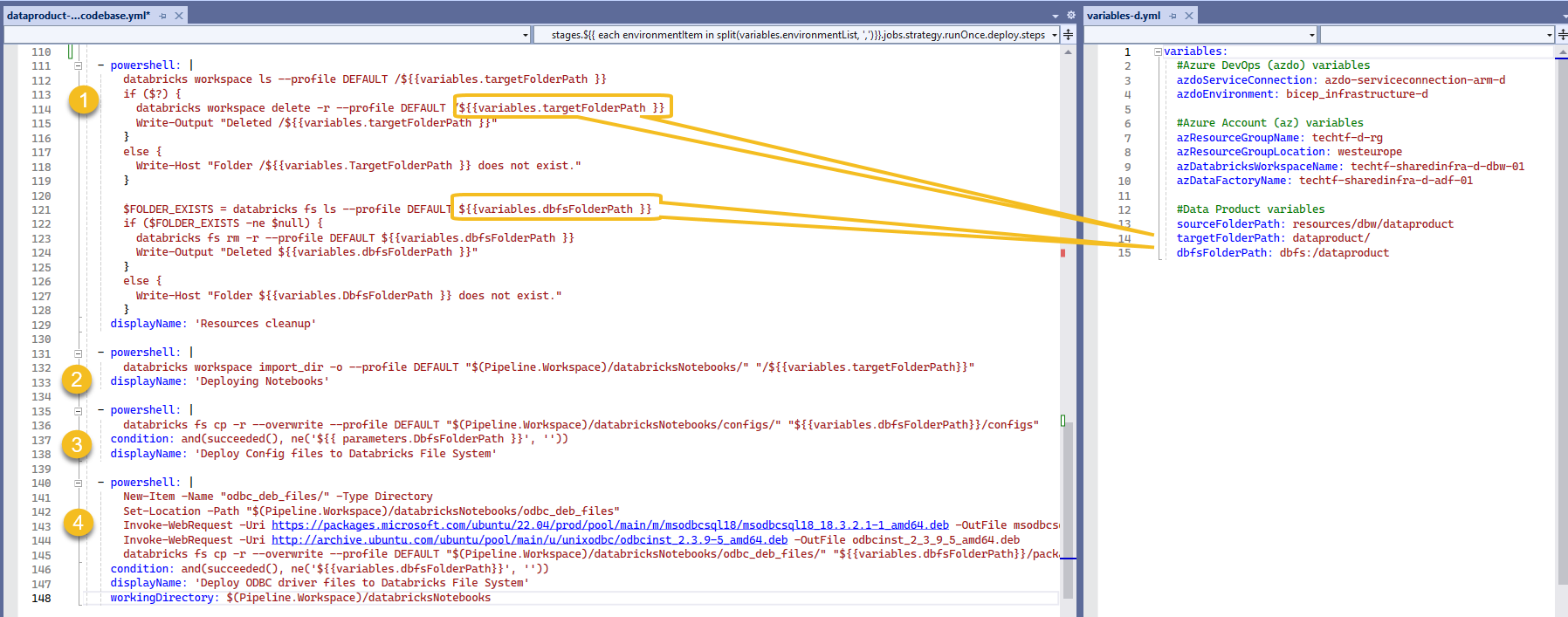
I'm basically using a truncate & load technique by removing the old workspace and DBFS folders (1) to import a new set of folders and content from our prev. crated artifact into the target folder path (2).
Some tasks are optional but commonly included in the pipelines I've seen, like deploying configuration files to DBFS (3) or to download drivers or other dependencies (4).
Outcome
As expected, we can see our notebooks deployed to the workspace...
and the drivers in DBFS 😁👍
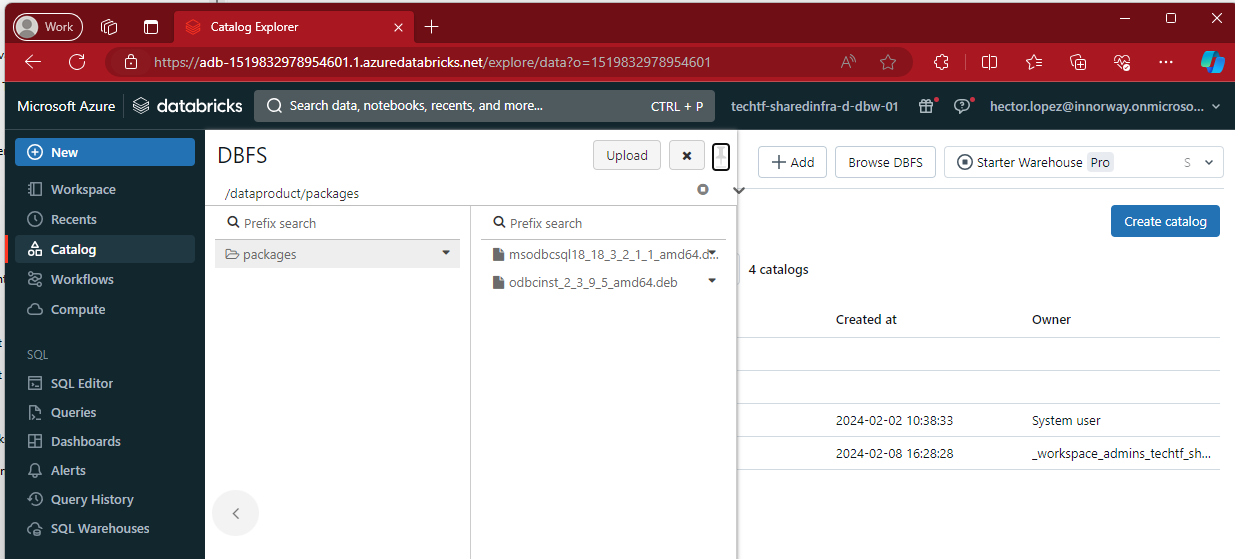
Execute the deployment
I explained the code, it is now your turn ...
Then, check on the video at the end of below article where I show you how to create the Azure DevOps pipeline
Hector Sven
Conclusion
So, why not just connecting the main branch into production-like environment? Some organizations chose this design pattern, however, there are potential risks associated with this practice, for instance, if a bug is introduced into the main branch, it could immediately affect the production environment;
In conclusion, whether or not to connect a repository branch directly to a production environment is a decision that should be made based on your team’s specific needs, workflows, and risk tolerance.



