Orchestrate your Notebooks via Azure Data Factory
ADF simplifies the orchestration of Azure Databricks notebooks, streamlining your data workflows and ensuring efficient data processing.


All good things must come to an end! This would part 4 (and last) of the series...
 Hector Sven
Hector Sven
Setting the stage
A discussion on whether or not use Azure Data Factory and Databricks together is like discussing whether or not to use a hammer and a screwdriver for any purpose: they are simply different tools, each with unique capabilities and you will achieve a superior result by using the strengths of both.
While both services offer connectivity to various data sources, Databricks is more versatile for analytics and machine learning workloads, whereas ADF excels in data movement and integration tasks, then the goal is to ...
I have been publishing several articles that would support the solution presented below, in particular I would recommend for you to take a look at this one Automating ADF's CI/CD with Selective Deployment (Generation 2) and from my previous series...
Hector Sven
Solution
On the next part of the article, I'll explain just the most relevant parts of the code
As shown on Provision your Workspace infrastructure with BICEP we output workspace's Azure Resource ID and URL.
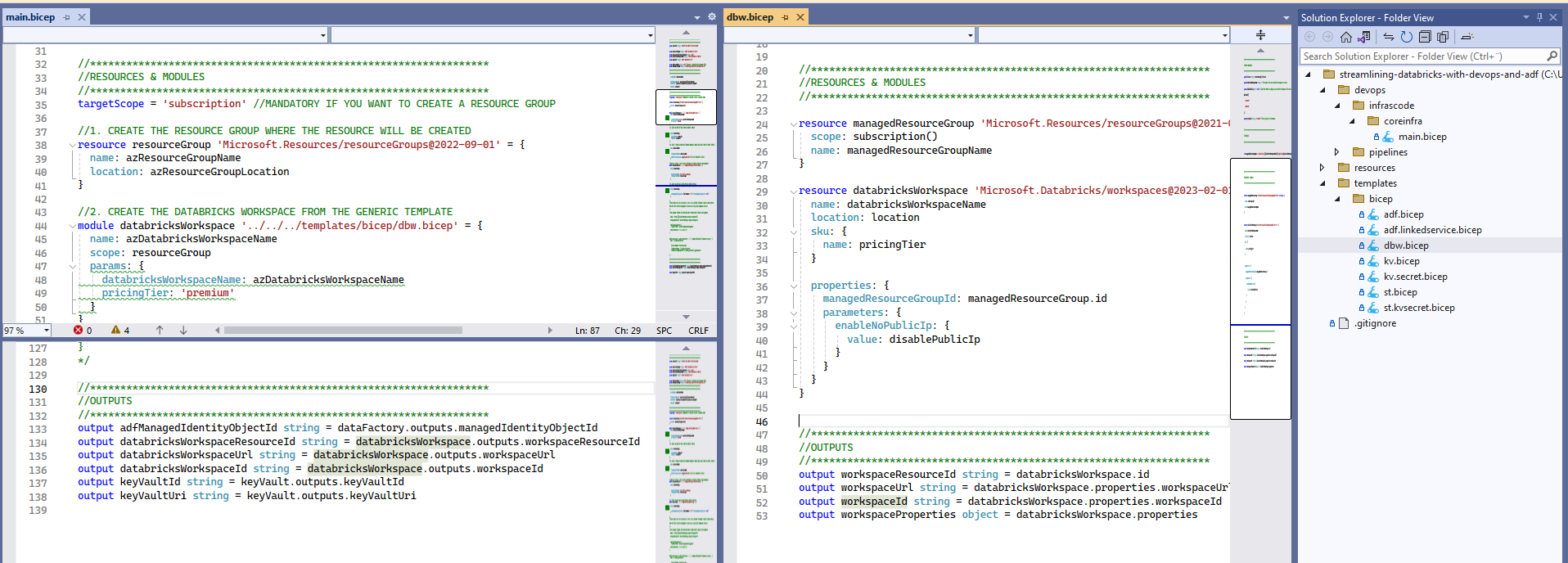
We are going to use this information to create parameterized ADF's linked services and global variables using a slightly modified version of the Automating ADF's CI/CD with Selective Deployment on Shared instances (Generation 3) where I create a "tokenized" version of my configuration Configuration files
"This files are use for replacing all properties environment-related, hence, its expected to be one per environment" (ref. ADF Selective Deployment G2)
Parameterized linked services
I think is a best practice for any ADF setup to create parameterized linked services, hence, following this best practice I create one for New job cluster and another for Existing interactive cluster as shown below.
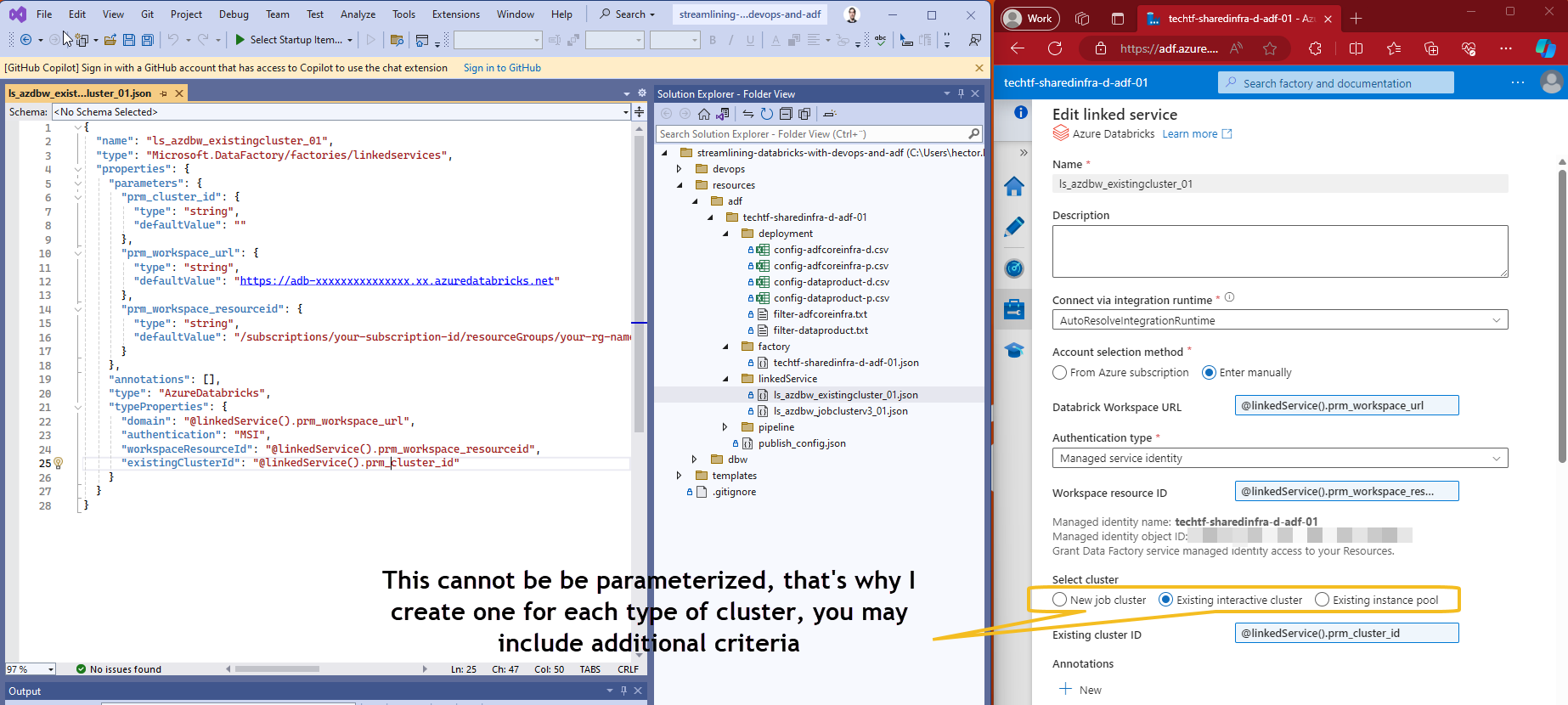
Additional information on these two options:
- New job cluster. Designed for running specific jobs or tasks within your Databricks workspace, ideal for isolated, short-lived workloads; incurs cost only during job execution.
- Existing Interactive Cluster. Intended for interactive data exploration and collaboration using Databricks notebooks, use when you want to reuse an existing cluster that’s already running; incurs cost as long as the cluster is running
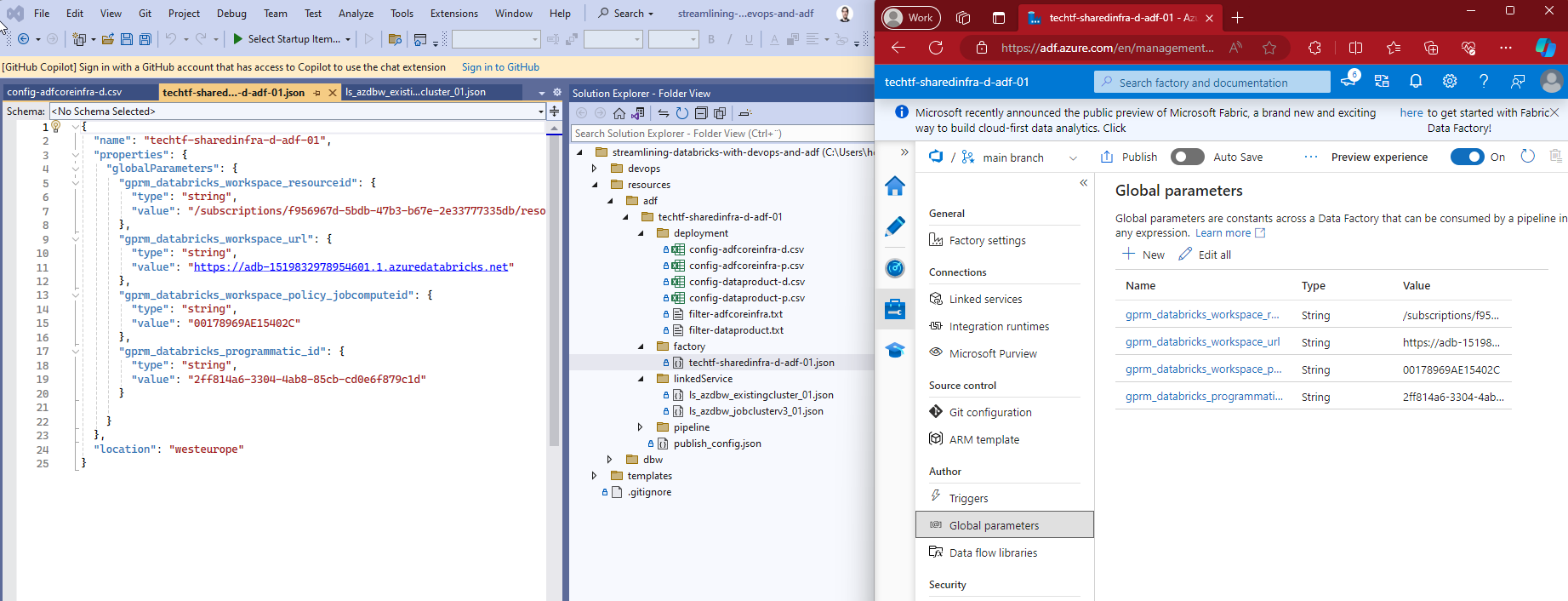
Parameterized Global parameters
From MSFT on Global parameters in Azure Data Factory
"[...] are constants across a data factory that can be consumed by a pipeline in any expression. [...] When promoting a data factory using the continuous integration and deployment process (CI/CD), you can override these parameters in each environment."
The idea is to make available our shared Databricks workspace as easy and consistently as possible throughout environments.
Tokenizing selective deployment Config files
As advanced, we are going to use a "tokenized" version of our selective deployment Config files and use Replace Tokens extension by Guillaume Rouchon with the values generated while Provision your Workspace infrastructure with BICEP
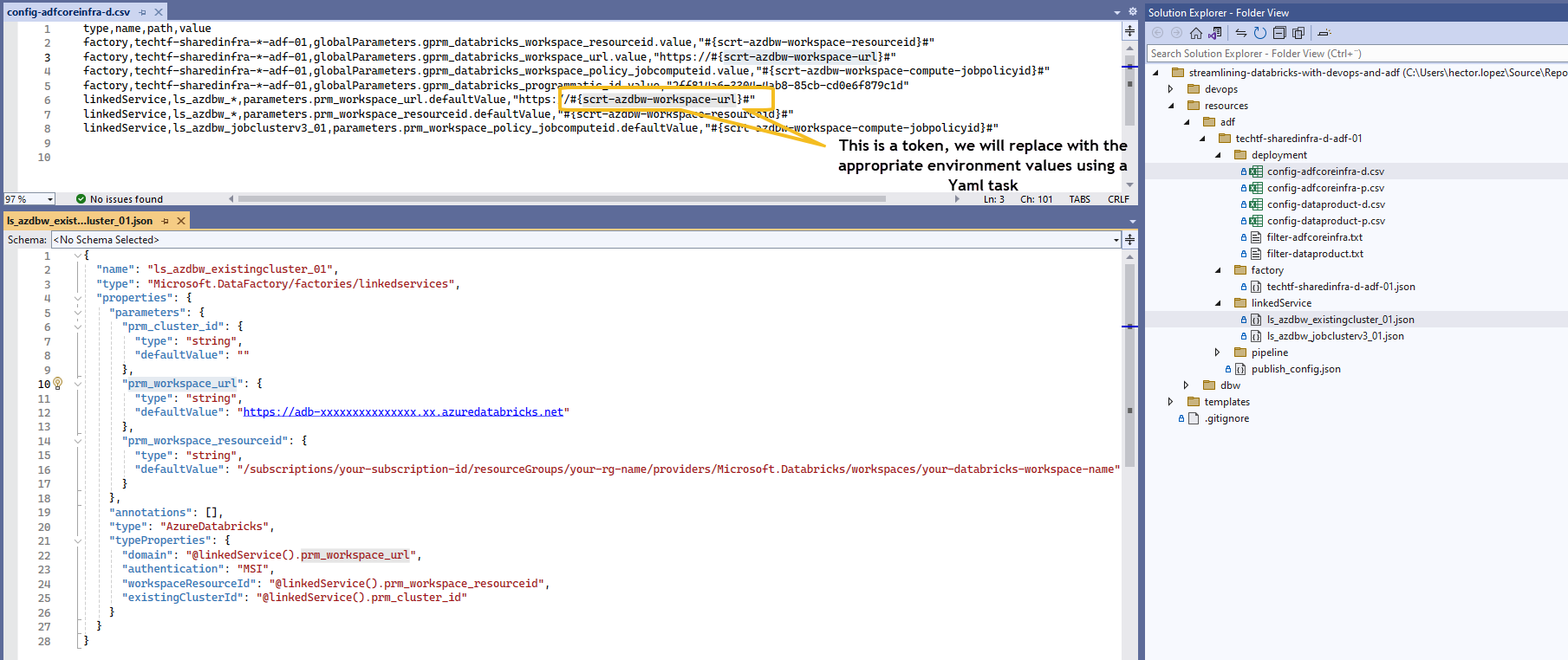
I'm using default token's prefix #{ and suffix }# as documented by the extension.
Replacing tokenized values
Output values from the IaC stage are stored on the environment's Key Vault (1) to be re-used. In the deployment stage (2) we first call AzureKeyVault@1 task to make available as variables all the secrets listed in the filter (3), we then create a copy of our tokenized config files in the Build.ArtifactStagingDirectory (4) for tokens to be replaced by the values collected and fetch from key vault using the Replace Tokens task (5)
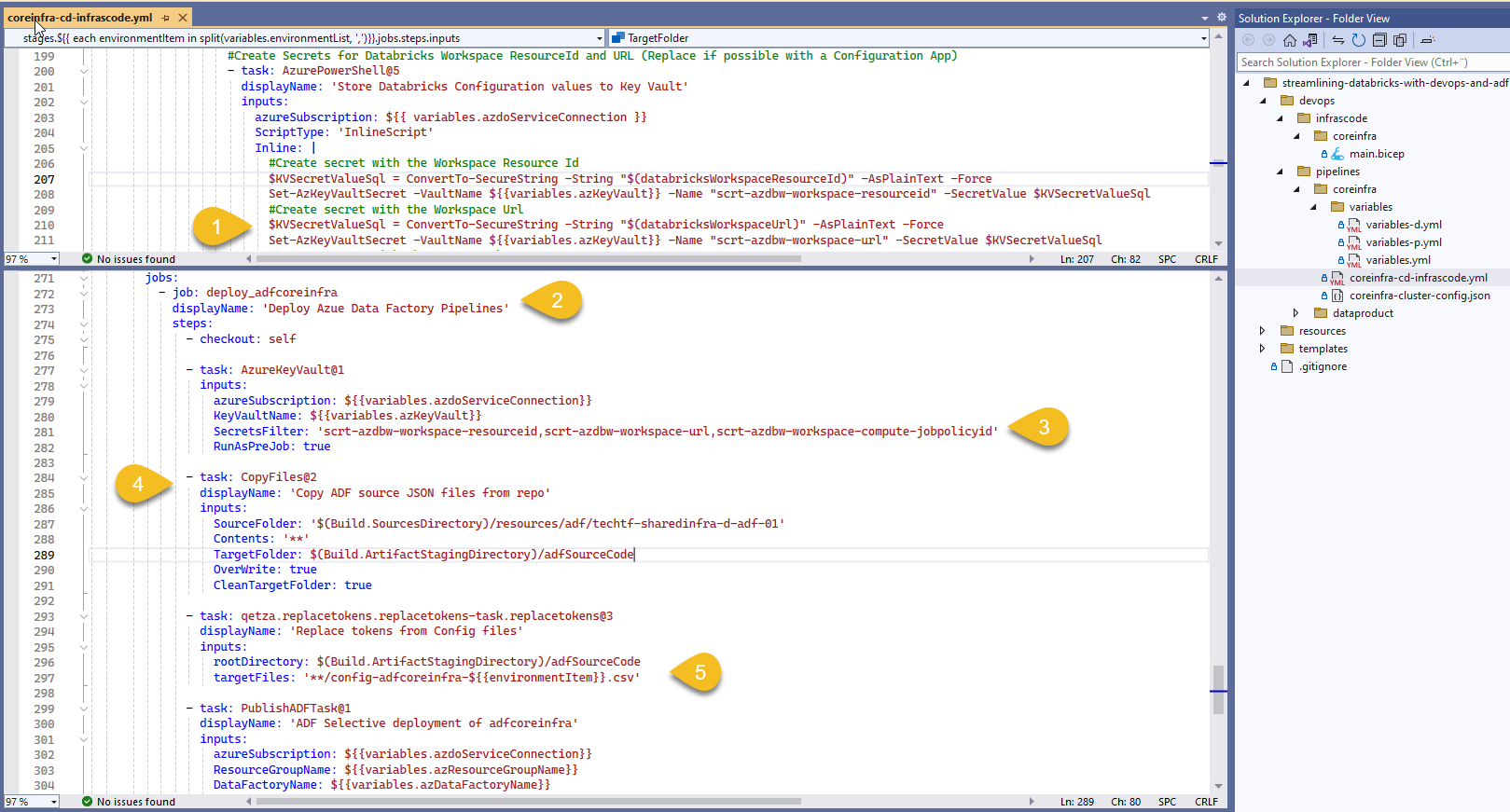
Finally we deploy linked services and global variables grouped as ADF's Core Infra (adfcoreinfra)
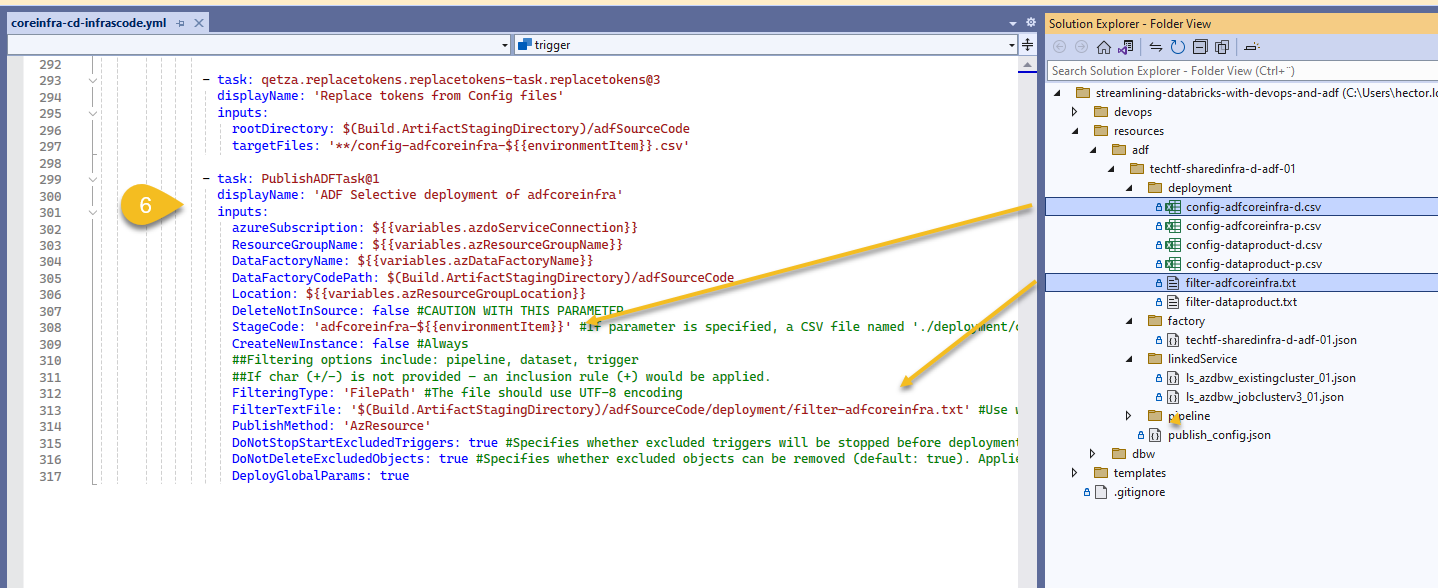
I explain more on this concept on my article Handling Infrastructure in Azure: Shared vs Data-Product, in a nutshell, ADF's key top-level components are Pipelines, Datasets, Linked services Data flows, Integration Runtimes... I divide them into two categories:
- Shared (aka adfcoreinfra). Integration runtimes, Linked services, Managed virtual network (if any) and Configuration/Global variables
- Data-Product. Datasets, Pipelines, Dataflows and Triggers
Execute Core Infrastructure pipeline
Get the code from AzDO Git repository streamlining-databricks-with-devops-and-adf and deploy the whole infrastructure linked together 😁🤞!
Finally, let's call some Notebooks!
Assuming that you followed the series and Deployed Notebooks across environments with DevOps YAML Pipelines , I'll jump right to Azure Data Factory's Live Mode (1) and from Factory Resources, create a new pipeline (2)
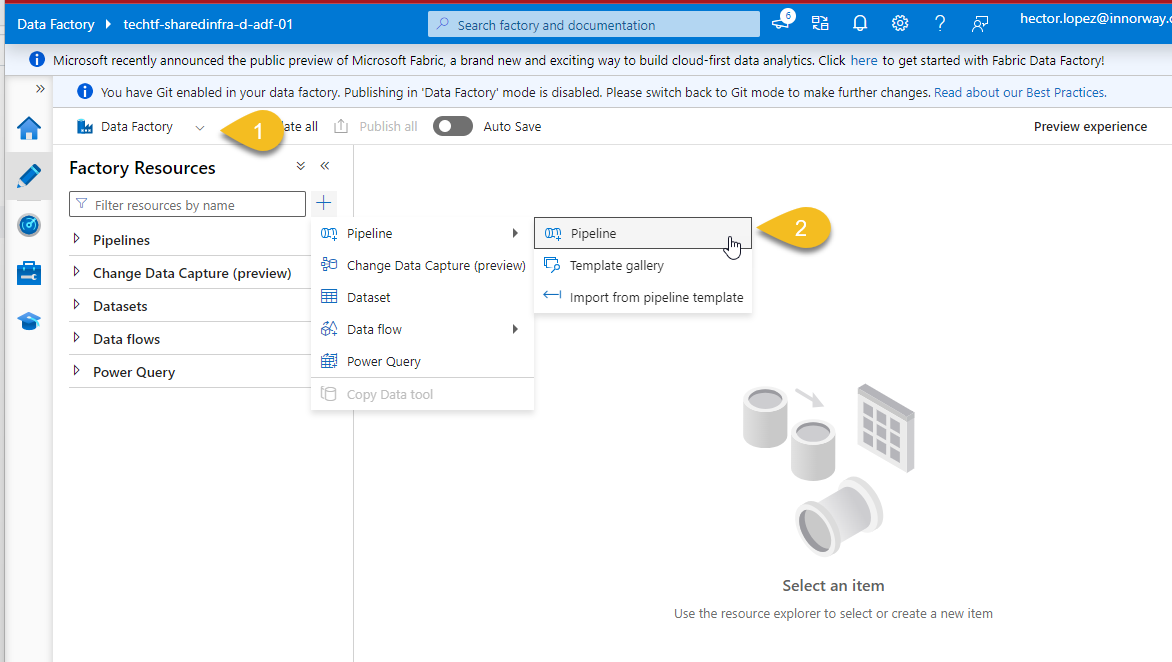
Add a new Activity to your pipeline, use the Databricks Notebook (1) and go to Azure Databricks (2)
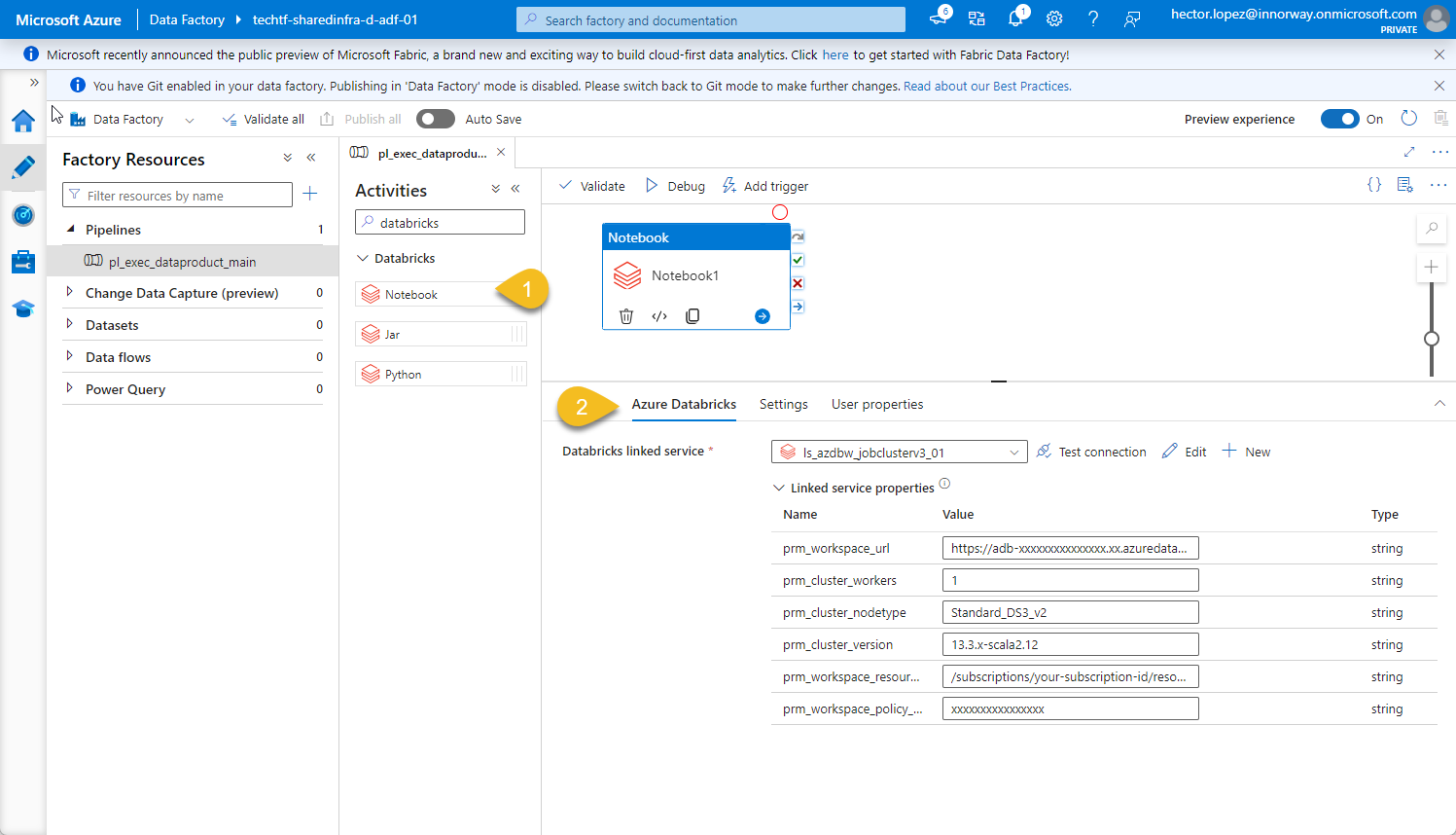
Place your self in linked service property prm_workspace_url (1) and click Ad dynamic content (2)
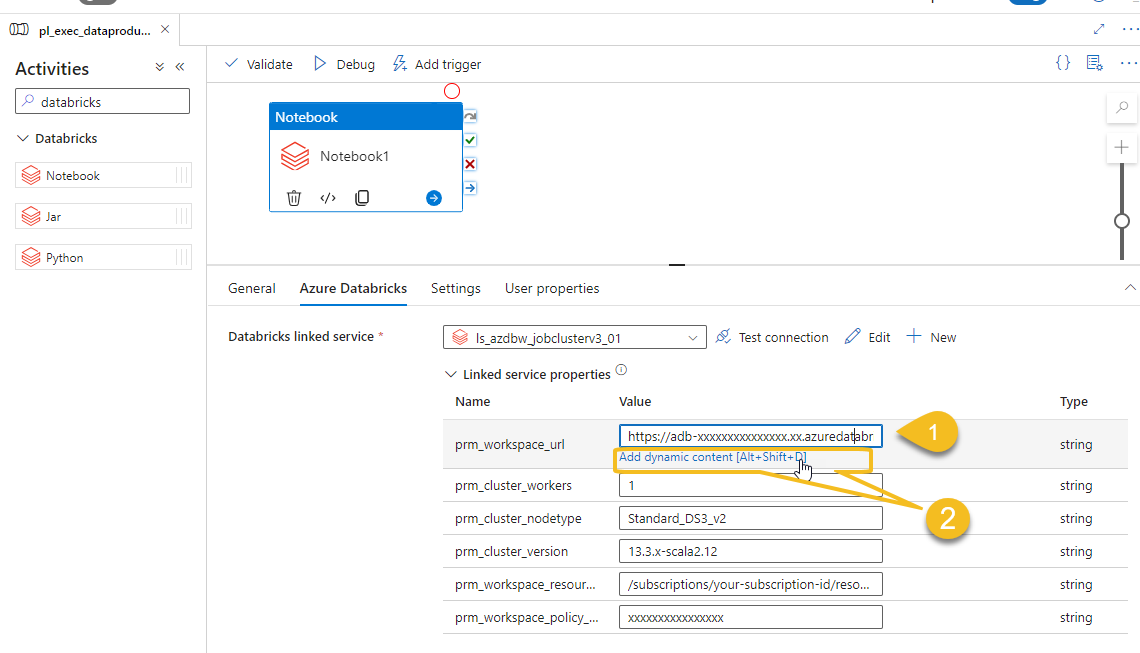
And use the corresponding global parameter corresponding to Databricks workspace URL
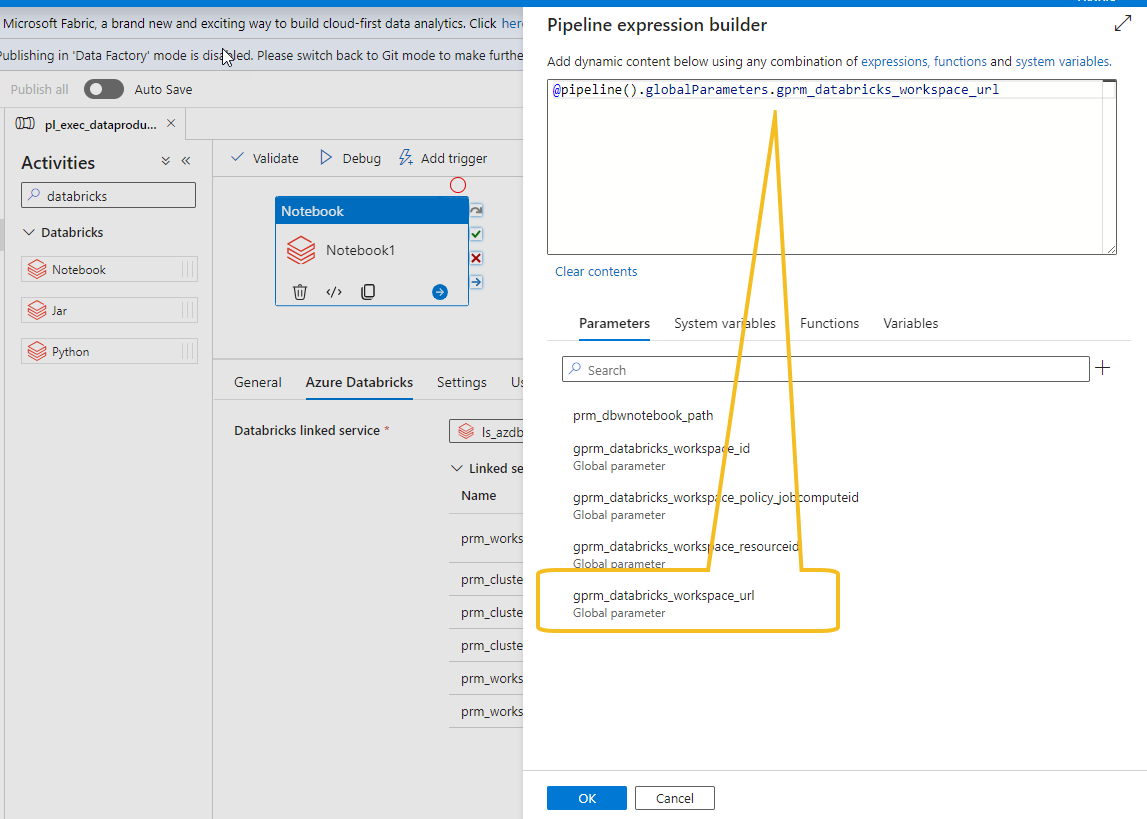
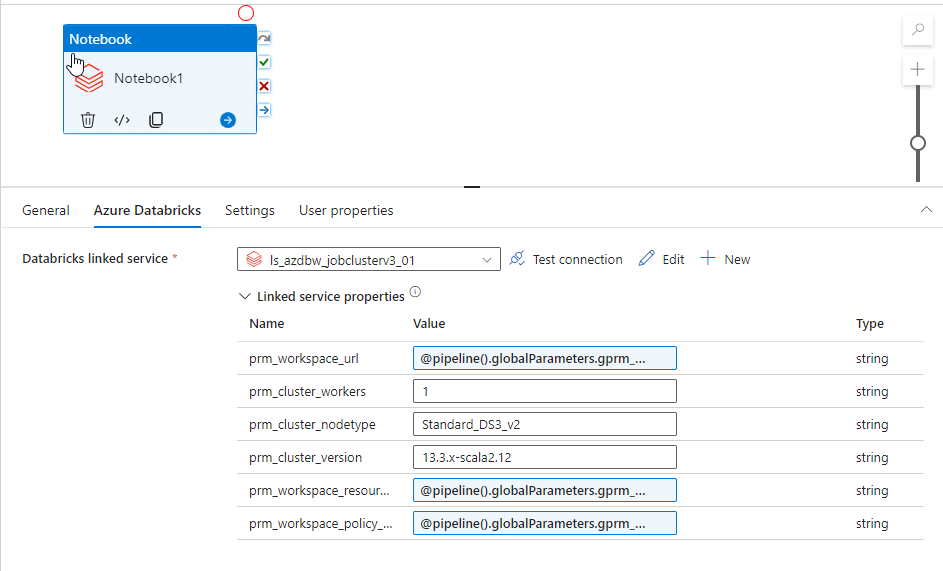
Repeat the operation associating the each linked service parameters to its corresponding global variables
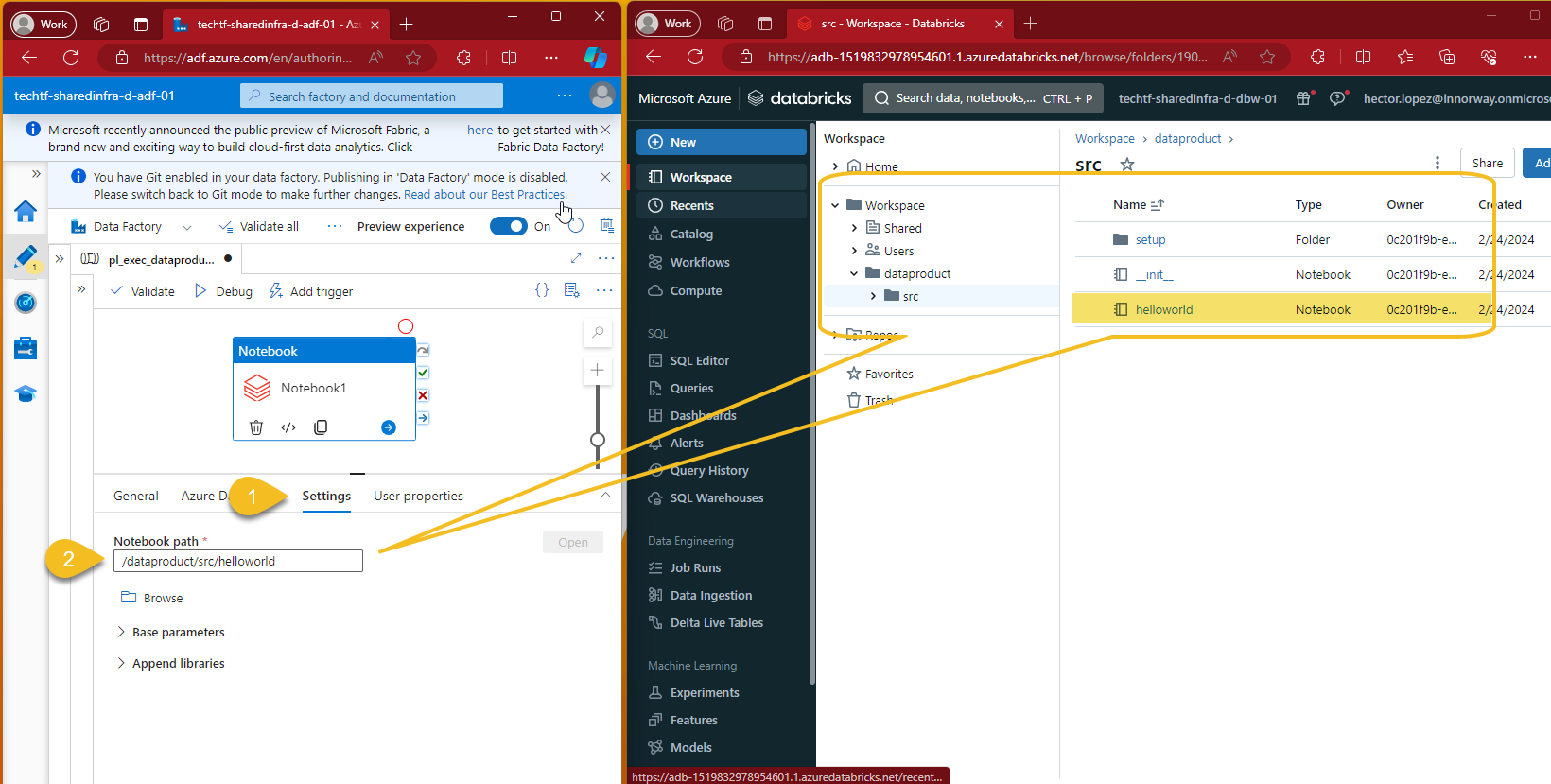
Configure Databricks Notebook activity settings (1) with any existing Notebook path (2) deployed on the Workspace
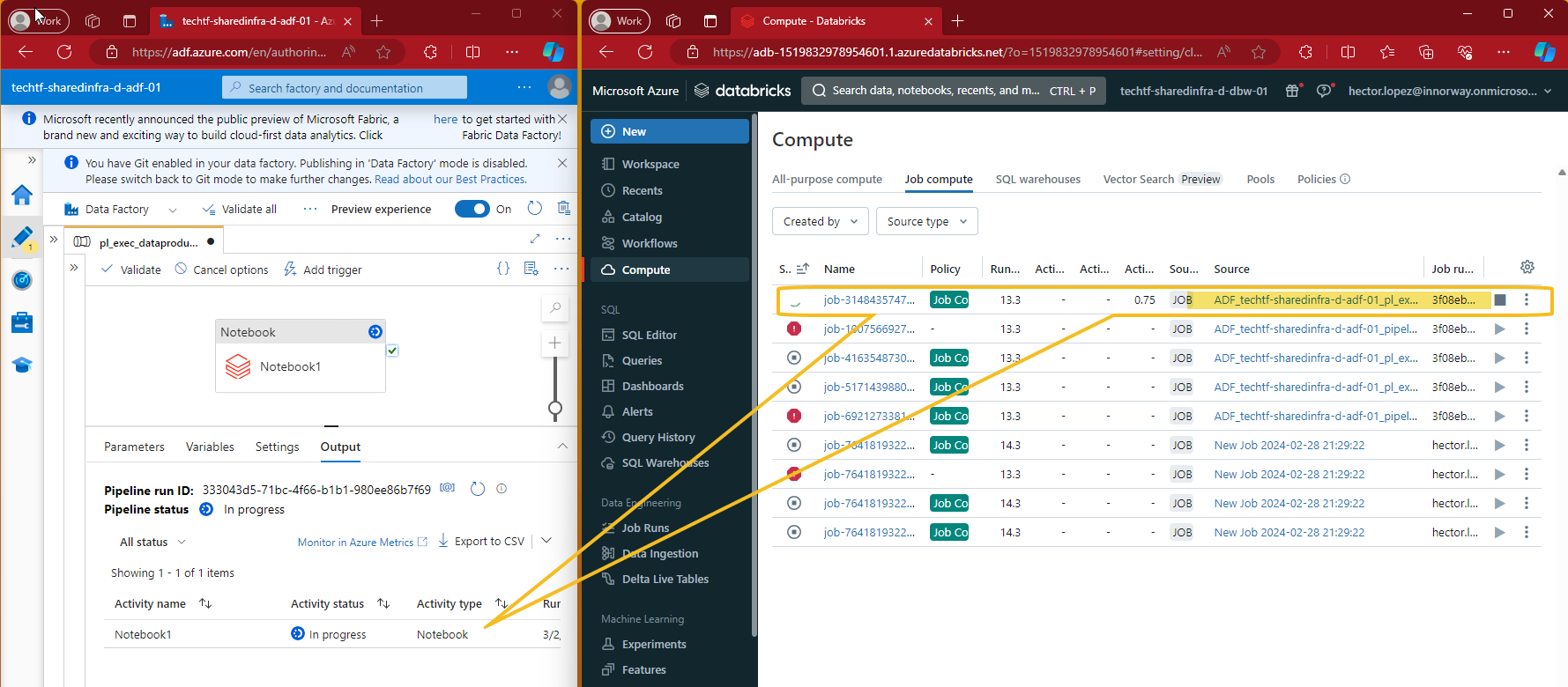
As expected, running the pipeline will create a Job Compute in the Databricks Workspace 😎👍
Call to action
I explained the code, now is your turn to ...
I'll create a bonus article to show you how to call Databricks jobs, don't miss it and subscribe 😉



