Provision your Databricks Workspace infrastructure with BICEP
Discover the power of BICEP in provisioning a robust Databricks workspace infrastructure, including the Azure Data Factory, Key Vault and Storage account; I'll use some PowerShell to configure RBAC permissions between resources and I'll show you how use the logging command task.setvariable


Welcome 😁! This would be Part 1 of the series ...
 Hector Sven
Hector Sven
Setting the stage
Buckle up as this would be quite a ride, but I hope a useful one at very least 😅🤞 from my previous examples, this example's complexity is higher in at least one order of magnitude, nonetheless, necessary to meet real world solutions.
Solution
On the next part of the article, I'll explain just the most relevant parts of the code
Deploying the Infrastructure
Of course with are going to start with the start of the show... Databricks Workspace's BICEP! Perhaps you will find shocking how easy this template looks like right? And that is exactly the point, is that easy!
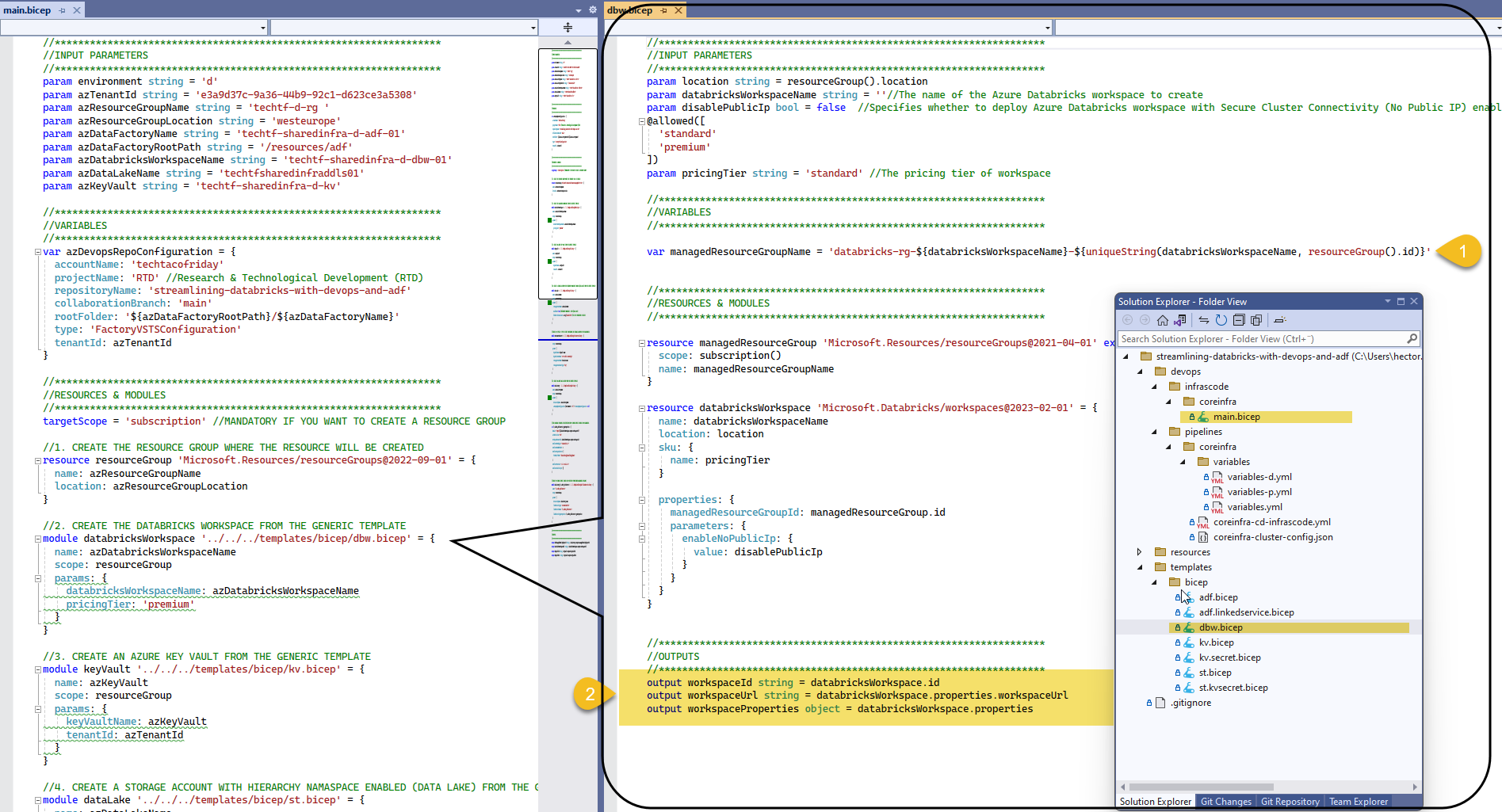
I want you to take note on the fact that each Databricks Workspace creates along with it a managed resource group (1), in a nutshell, is a resource group that holds related resources for an Azure solution; I also want you to observe the Output section (2), we are sending back the Id and Url of the workspace and we will configure ADF liked services with this information, hence, streamlining the pipeline 😁.
In our example environment, we will be creating some additional resources, in several of my prev. articles, I showed an example of Azure Data Factory, but I'm going to show you something new!!! Let's use BICEP to create a linked service and use the output values from Databricks directly.
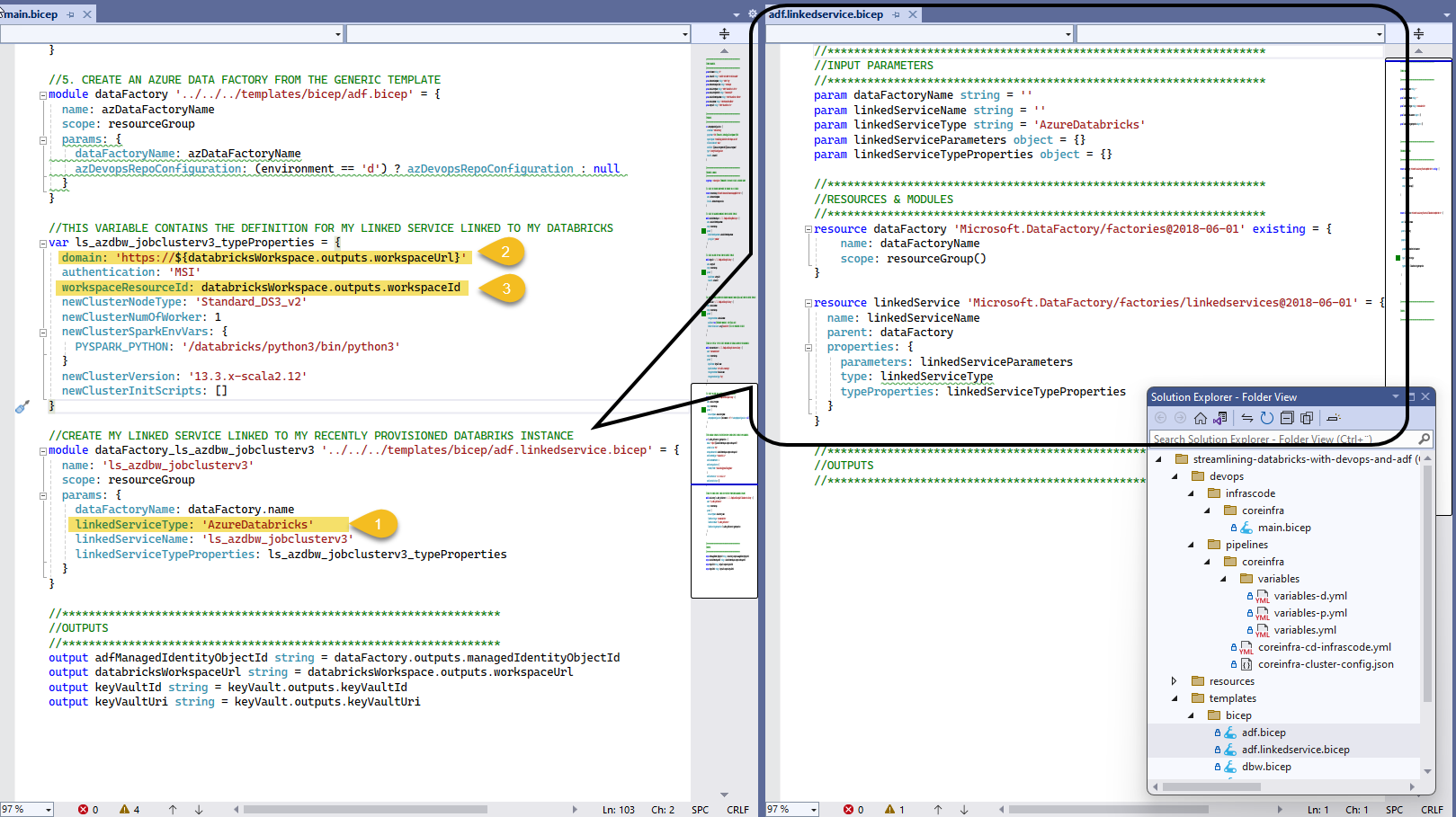
As shown, we are creating a linked service of type AzureDatabricks (1), and using the return output from Databricks BICEP module, we configure our linked service with the domain (2) and workspace resource id (3)
Following the same logic, we will also deploying an Azure Key Vault, a Storage Account with its Hierarchy namespace enabled (named Data Lake in the example).
Retrieving values from Deployment
There are a few additional tasks that are not possible to achieve via BICEP, but in order to complete it, we DO need its output, this is how I do it.
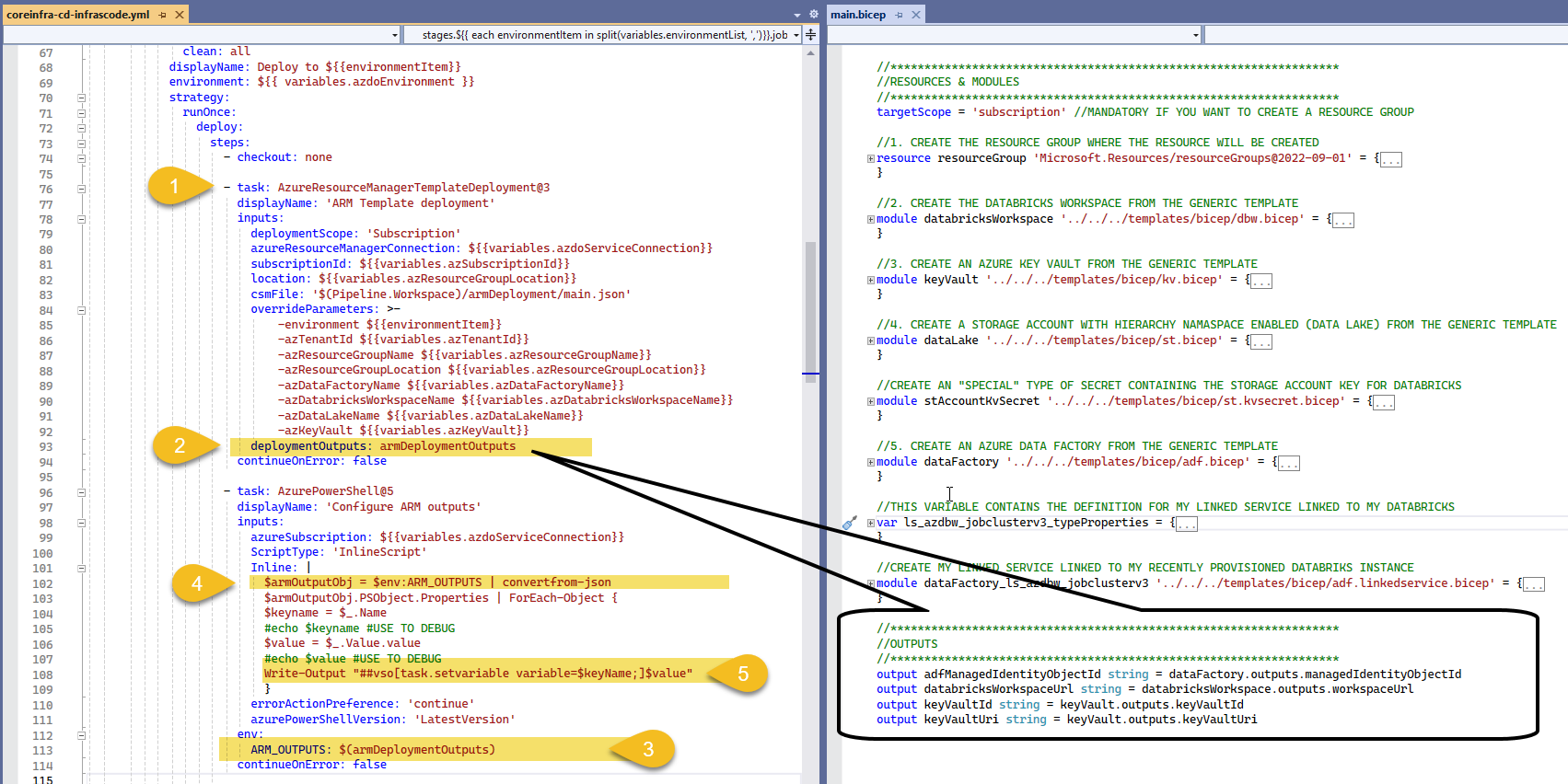
Once task Azure Resource Manager template deployment (1) is complete, we provide a name to the outputs section using the option deploymentOutputs (2), we us ARM_OUTPUTS (3) to capture the output values, we then convert from json to and object and we iterate using ForEach and create variables that can be used in subsequent tasks in the pipeline using the logging command (5)
Write-Output "##vso[task.setvariable variable=NameOfVariable;]ValueOfVariable"Setting RBAC permission with Power Shell
We will use an Azure Power Shell task to set RBAC permissions
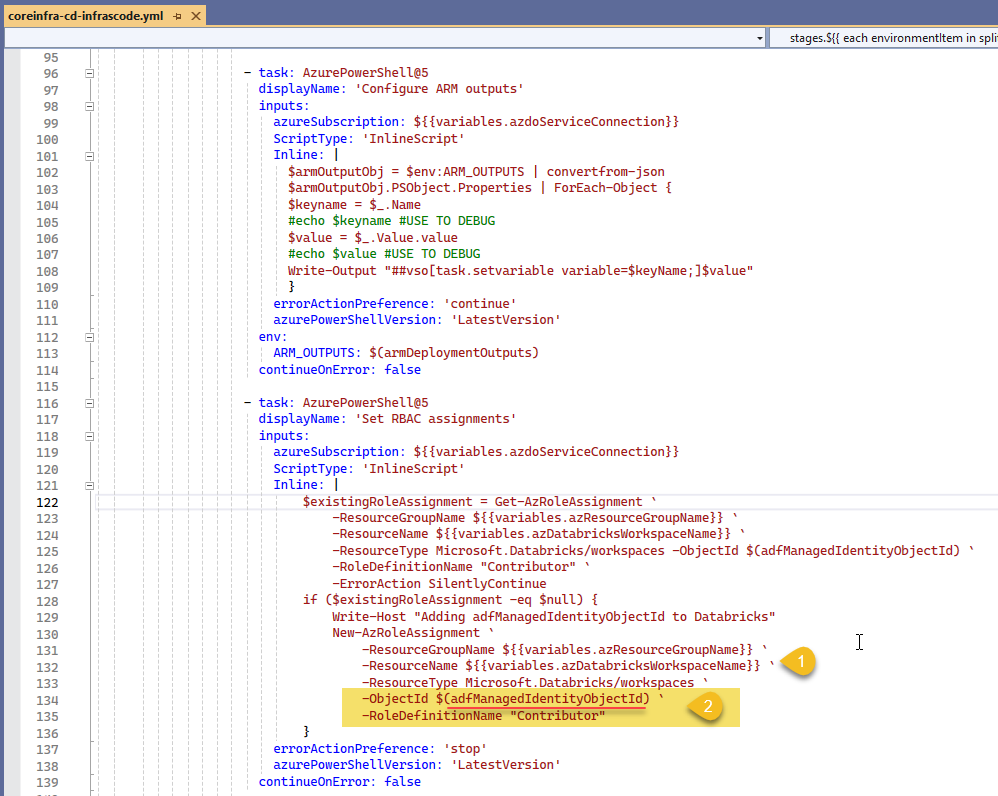
We have the Databricks workspace name from our variables (1) and we use the ADF's Object Id (2) extracted from the outputs and use with New-AzRoleAssignment PowerShell cmdlet
Preparing the agent and creating a KV Secret scope
Tasks 1 to 3 prepare DevOps pipeline pool agent, first by indicating what version of Python to run (1), generate the Entra's ID authentication token (2) for the service connection, it then creates the [DEFAULT] configuration profile (3) for the workspace.
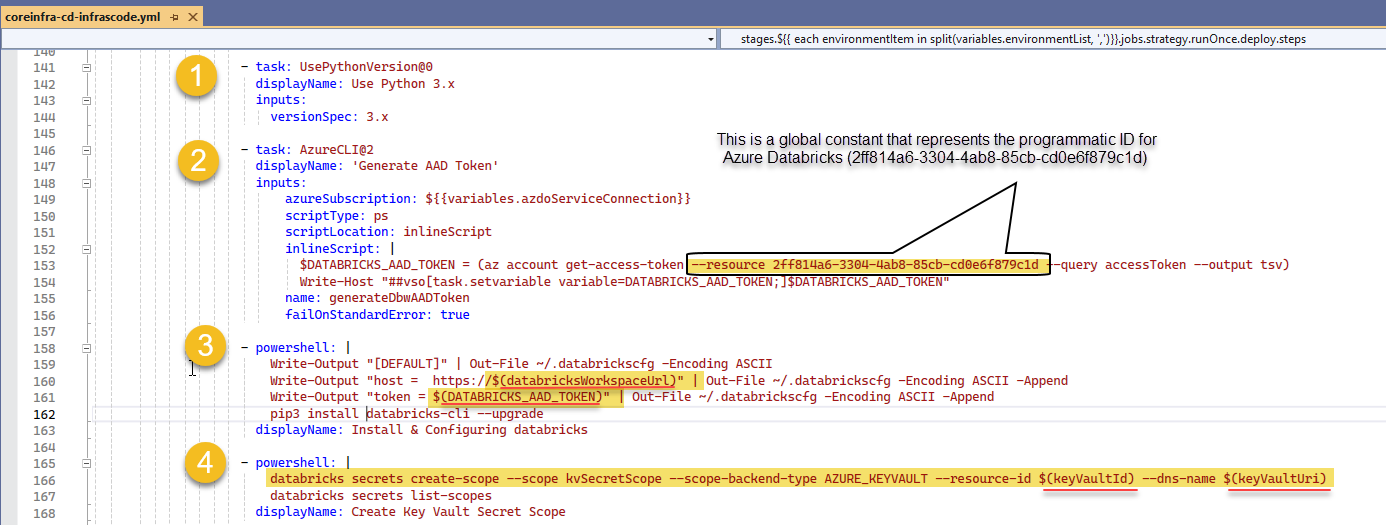
We finally create the Secret scope (4) to the prev. created Azure Key Vault for secure and centralized storage of application secrets.
Create the Workspace Cluster
Last but not least... creating the cluster 😅! Remember that we are still under the context of our previously created [DEFAULT] configuration profile in the a DevOps pipeline pool agent powering our job, therefore, we just need to call via Databricks CLI for a new cluster defined as a json file and get its ID (1).
Also notice how we we are now using isOutput=true along with the task.setvariable, the reason is because we are shortly going to use another job, this property allows variables to be fetch as a dependency as show below.
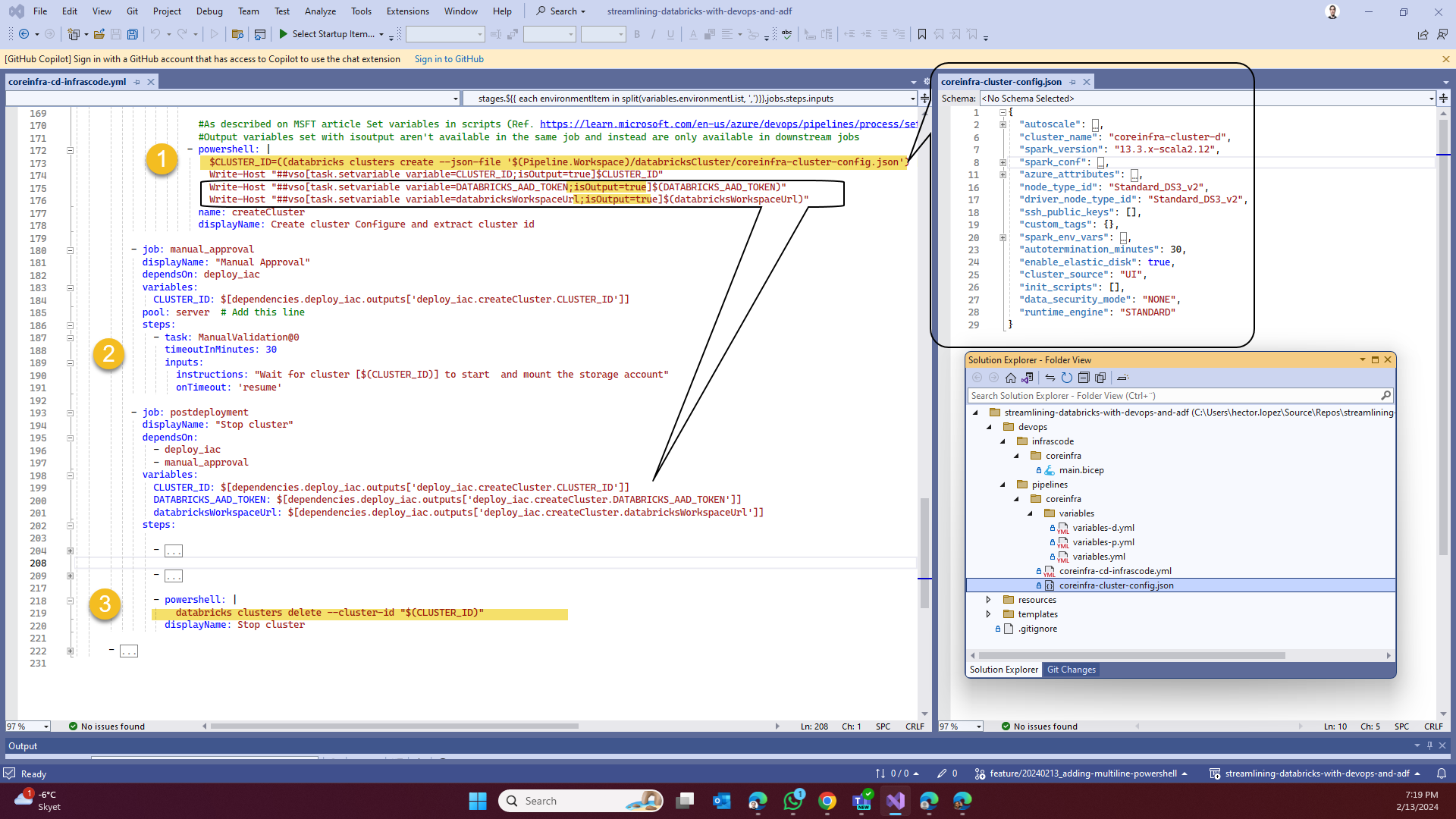
If you work with Databricks before, you'll know that clusters take some time to start 😬 and since this is an asynchronous operation, I just use a Manual Validation task to check the cluster status before continue (2), there's other ways to "wait" using Delays or loops to check for the cluster status, use the one that fits your needs, I will leave two additional methods in the code 😁.
For our gran finale, we just terminate the cluster (3) to avoid any unnecessary costs 😊
Execute the deployment
I explained the code, it is now your turn ...
Then, check on the video at the end of below article where I show you how to create the Azure DevOps pipeline
Hector Sven
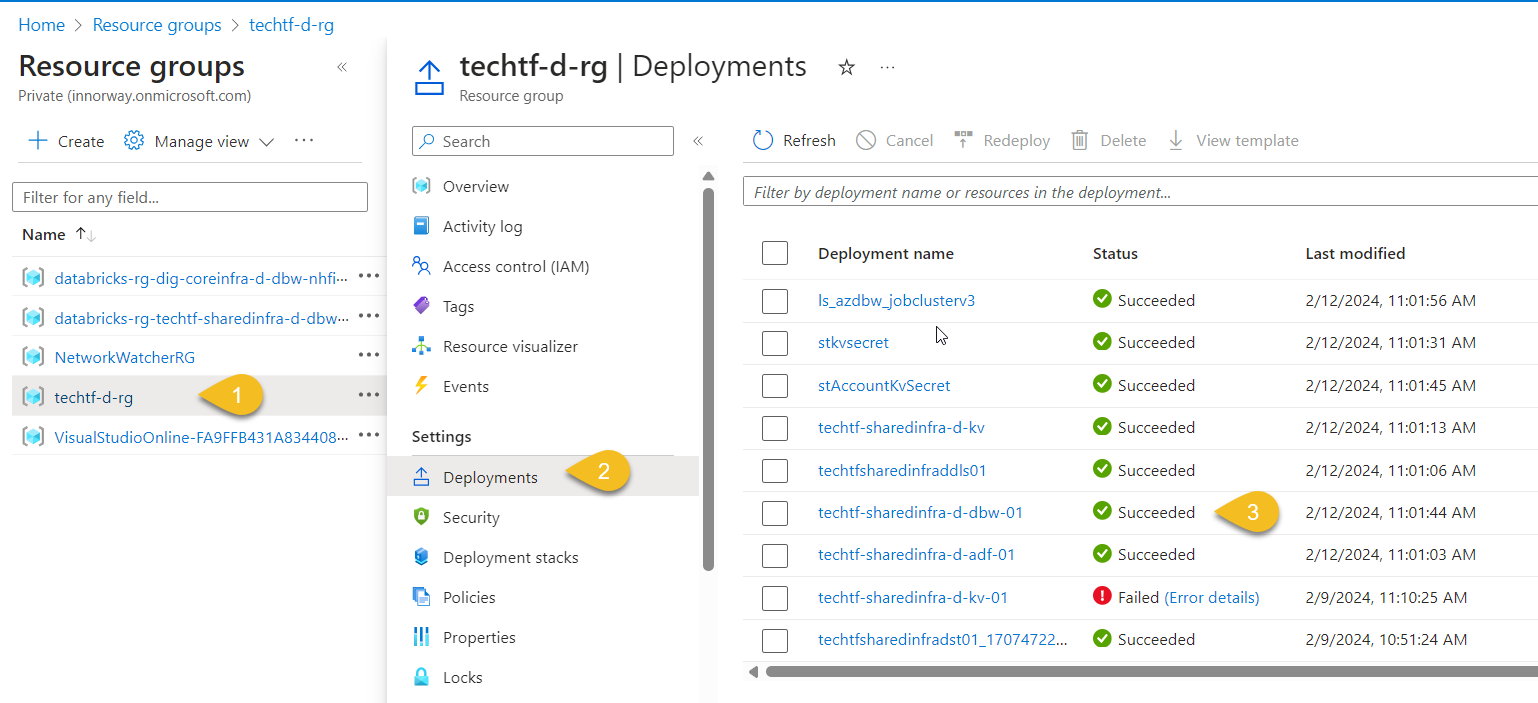
Run the pipeline and monitor the deployment by clicking on your Resource Group (1) > Deployments (2), you can view each resource's deployment status (3)
Call to action
On my next article, I'm going to talk about how to use Users & Groups Management via Azure's Entra ID for your Databricks setup, if you like to get it directly via email, below is the subscription button... wish you all the best!



