The Elusive artifactId in Fabric Data Pipelines and Where to Find It
Struggling to find the elusive artifactId in Fabric Data Pipelines? You’re not alone! This critical identifier isn’t the lakehouseId, and worse—it’s hidden from the API. Discover where it actually resides, why it’s breaking CI/CD automation, and why Microsoft must make it accessible.


Introduction
As a developer working on Fabric automation, you expect a smooth workflow when setting up data pipelines. However, when dealing with the Copy Activity in Fabric Data Pipelines, you may stumble upon an unexpected roadblock—an enigmatic artifactId that appears in the JSON definition of the pipeline but is nowhere to be found within Fabric’s UI or API responses.
In this article, I will walk you through this issue, using a simple example of a data pipeline that copies data from an open-source parquet dataset into a Lakehouse. Along the way, we’ll uncover why the artifactId is so elusive, where it’s actually stored, and why its current inaccessibility completely disrupts automation and CI/CD workflows.
Setting Up the Pipeline
Let’s start with a basic Fabric Data Pipeline:
- Source: A public holidays dataset in Parquet format, stored in Azure Blob Storage.
- Sink: A table in a Lakehouse within the same workspace.
- Workspace: Git-enabled, so we can inspect the code behind the pipeline.
The Copy Activity’s JSON definition contains a reference to this mysterious artifactId
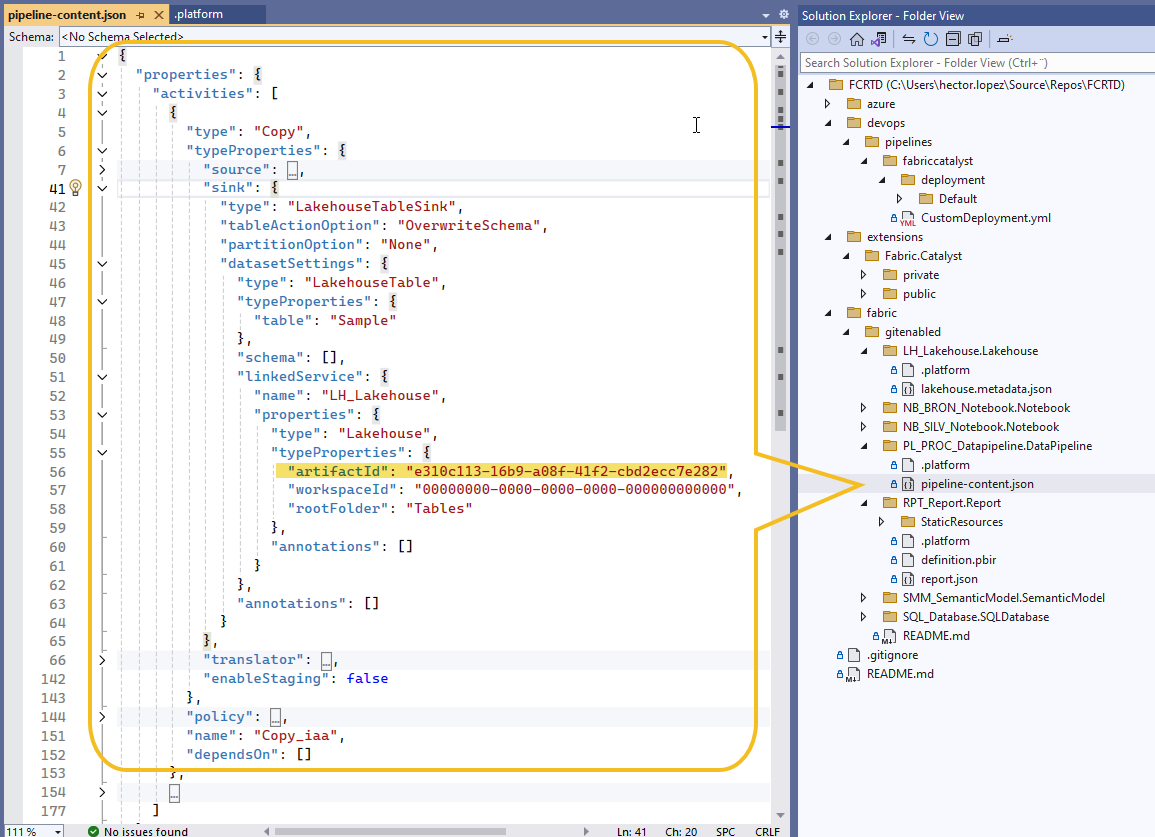
At first glance, it’s reasonable to assume this ID belongs to the Lakehouse or a related connection. But when you try to locate it… well, good luck.
artifactId is NOT the lakehouseId! Before we go any further, let’s clear up a common misconception: Many developers assume that artifactId and lakehouseId are interchangeable, but they are completely different things... this is why the issue is so frustrating—you can easily get the lakehouseId, the artifactId a whole different story, keep reading! Where is the artifactId? (Spoiler: Not Where You’d Expect)
Let’s explore the possible places where we might find this artifactId:
- Lakehouse Connections → Nope, not listed there.
- Fabric REST API (
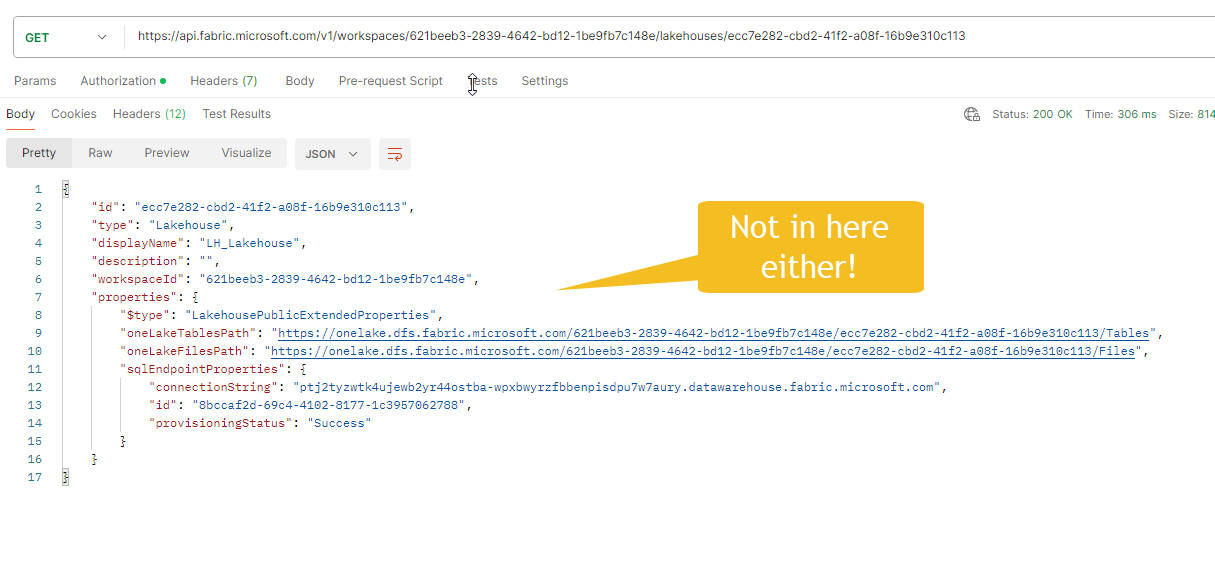
GET /workspaces/{workspaceId}/lakehouses/{lakehouseId}) → No trace ofartifactIdin the response. - Fabric UI → Nowhere to be seen.
It’s as if this ID was generated in secret, hidden from developers who need it for automation.
Is not here Fabric REST APIs - Items - Get Item
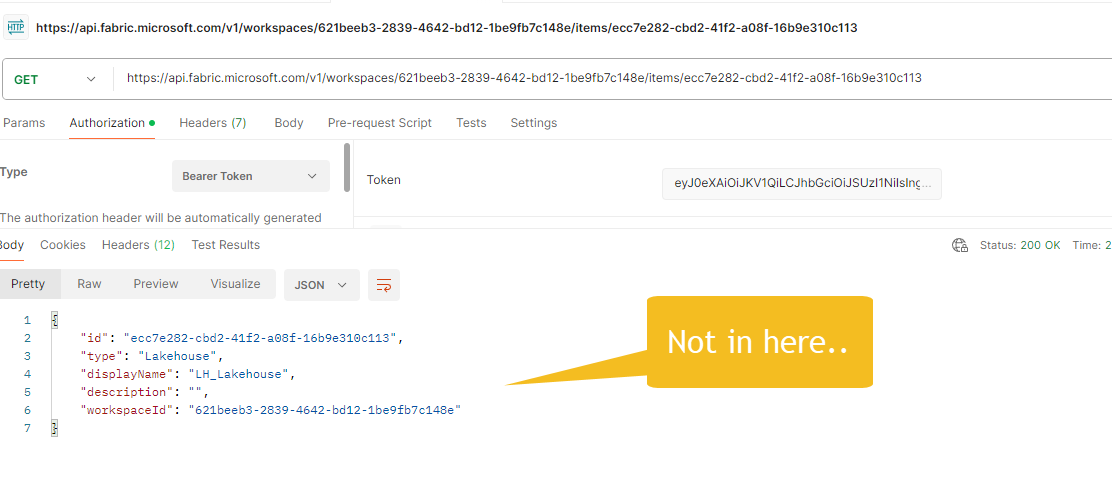
nor here Fabric REST APIs Items - Get Lakehouse
The Hidden Truth: The artifactId is Actually the logicalId
After some digging, I found that the artifactId does exist—but it goes by a different name inside the Fabric system! If you inspect the .platform file of a Lakehouse, you’ll find an entry labeled logicalId, which matches the artifactId used in the pipeline JSON.
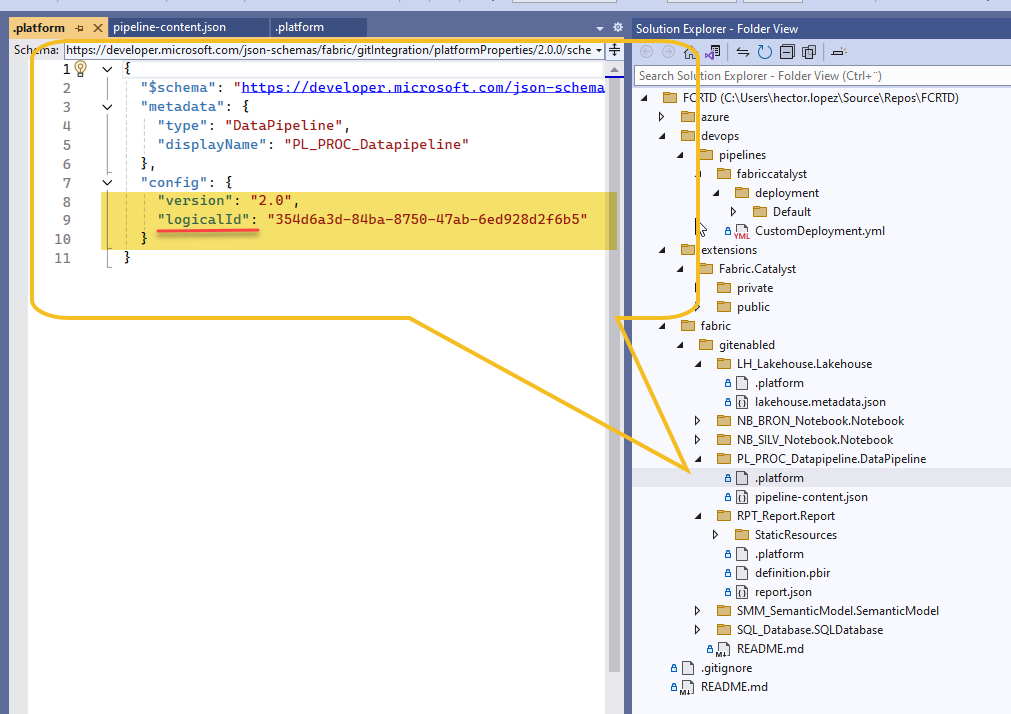
This means that if we could access the Item Definition of a Lakehouse, we’d be able to retrieve this artifactId (or logicalId) programmatically.
The Problem: The API for Item Definitions Doesn’t Exist (Yet?)
Naturally, the next step is to use the API to fetch the Item Definition, extract the logicalId, and use it for automation. However, there’s a big problem:
This means that there’s no reliable way to programmatically fetch the artifactId, making automation impossible without manual workarounds.
Why This Matters for CI/CD and Automation
For proper CI/CD pipelines, environments should be dynamically configurable. If you’re deploying a pipeline across Dev, UAT, and Prod, you need to modify the sink to point to the correct Lakehouse. But without access to artifactId, this becomes an absolute nightmare.
The only workaround?
- Manually create all required Lakehouses ahead of time.
- Manually create dummy Copy Activities targeting each Lakehouse to extract the
artifactId. - Manually update the pipeline JSON with these extracted IDs.
This completely breaks the promise of automation and DevOps best practices.
Conclusion: Microsoft, Please Fix This!
For Fabric to be truly enterprise-ready, Microsoft must expose the artifactId (or logicalId) through a proper API.
Until then, developers will remain stuck with manual, hacky, and inefficient workarounds.
(Final CTA: If you agree, upvote this issue on the Fabric Community Forum!)



