Understanding ADF authoring modes and Publishing Cycle
Understanding authoring modes is of particular importance when we are trying to get our ADF into a Continuous Integration and Delivery (CI/CD) flow, this is why I will start by explaining what are Live vs Git authoring modes and how the publishing cycle works.


Welcome 😁! This would be Part 1 of the series ...
 Hector Sven
Hector Sven
Setting the stage
Based on my experience, what people struggle the most to understand on ADF is its authoring modes, I guess this is also why I people asked me what exactly happens when you click the "publish" button or when they don't know why "stuff" is missing when switching between modes.
But getting a good grasp of authoring modes is of particular importance when we are trying to get our ADF into a Continuous Integration and Delivery (CI/CD) flow, this is why I will start by explaining what are Live vs Git authoring modes.
Demystifying concepts
Let's start with the basics...
Authoring modes
Azure Data Factory (ADF) supports two: Live and Git. These modes represent different approaches to developing data integration pipelines within the ADF environment.
- Live Authoring
In Live Authoring mode, development and changes to data pipelines are made directly within the Azure portal's user interface via your preferred web browser providing a visual, code-free experience through an intuitive graphical interface. This mode is well-suited for quick prototyping, ad-hoc changes, and scenarios where collaboration among team members is not a primary concern as it lacks version control and collaboration features found in Git-based authoring.
- Git Authoring
Git Authoring mode is designed for more structured and collaborative development processes. It leverages the power of Git to manage changes to ADF artifacts. This approach brings benefits such as version history, branching, and the ability to work on changes concurrently while ensuring a controlled and auditable development lifecycle. This mode is particularly valuable when integrating ADF into a DevOps CI/CD (Continuous Integration/Continuous Deployment) cycle, allowing for automated testing, deployment, and version tracking.
Publishing Cycle
I don't think anyone would like to develop a data integration pipeline, that, once promoted from development to production, has to be manually executed by someone every day or every time something happens, right?
In ADF only published pipelines can be executed by triggers as part of its design and versioning approach, by requiring pipelines to be explicitly published before triggering it promotes a disciplined development & deployment cycle, hence, regardless of which method we choose to author changes...
The following diagram captures the authoring & publishing cycle
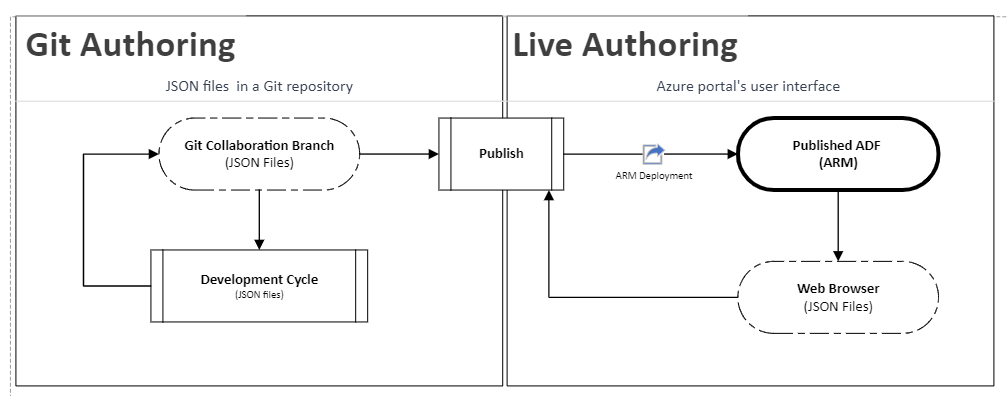
A few additional notes:
- Development Cycle. I recommend you to follow Modern software development practices (Section 6) from my recent article:
Hector Sven
It is now pertinent answering the question "what does the Publish button do in Azure Data Factory?"
How to use each authoring modes?
Ok, the straight answer is as follow:
This means production-like ADF instances are not going to be connected directly to any Git repository, so, how are we going to push our developed data integration pipelines? The answer:
Something like this:
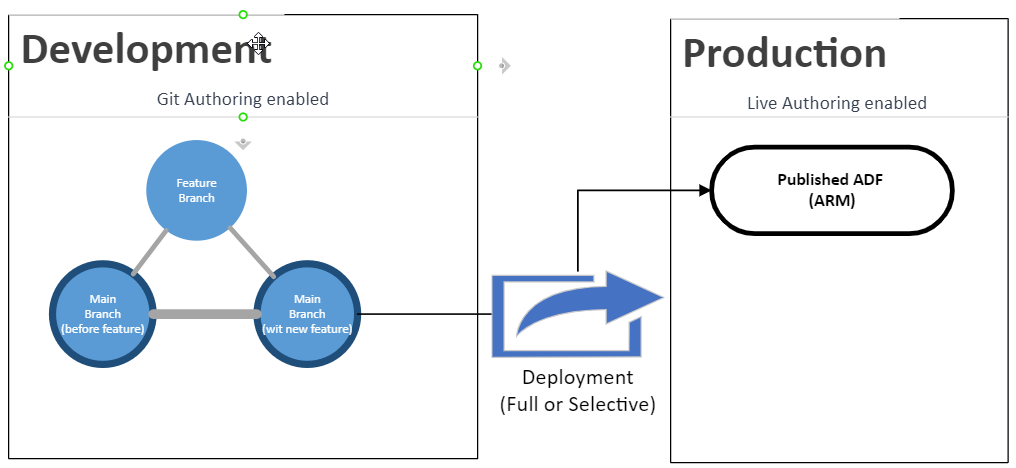
What happens behind the scenes?
I would like to show you how an azure data factory stores the code in the repository when Git-author enabled; let's say that you created an ADF configured as follow
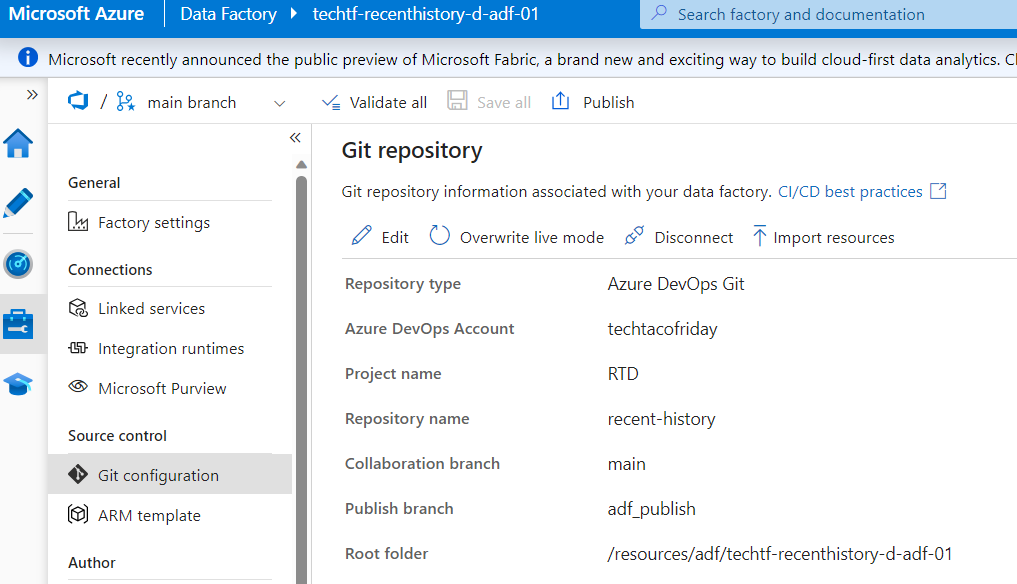
Following our development cycle following modern software development practices, we create a feature branch and add a simple pipeline, dataset, linked service and click Save All, this is how our feature branch will look (below right)
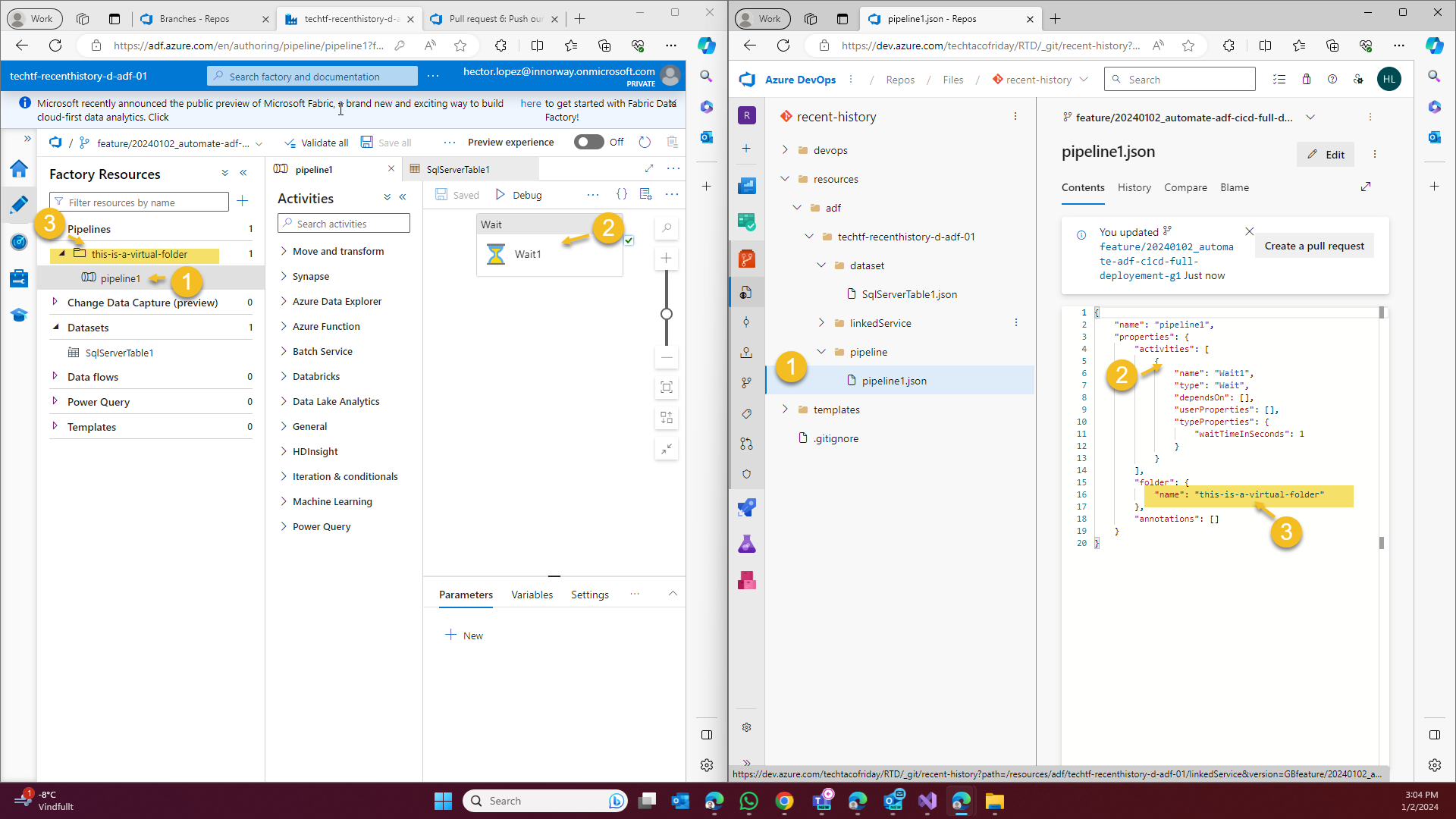
As indicated in the image, would like you to take the following notes.
- Notice how everything in ADF becomes a Json file in the backend and it's organized by folders named as the different types of components.
- All activities are defined within the pipeline files also using json notation, this allows for dynamic data processing and manipulation
- Notice how the folder structure in Azure Portal's GUI for is not reflected as folders in the pipeline folder, as shown, they are defined as one more property in the definition, this is MPORTANT and will become more relevant in the selective deployment.
I hope this will be a good theorical foundation to understand the rest of the series... stay tune and subscribe!



